
-
CENTRES
Progammes & Centres
Location

हा लेख AI F4: Facts, Fiction, Fears and Fantasies या मालिकेचा भाग आहे.
सोशल मीडिया प्लॅटफॉर्मवरील सामग्रीच्या मोठ्या प्रमाणामुळे, सामग्री नियंत्रणाच्या पद्धती बदलल्या आहेत. हा व्यायाम पारंपारिक समुदाय संतुलनाऐवजी एआय-संचालित स्वयंचलित संतुलन साधनावर अवलंबून आहे. सामग्री मॉडरेशनसाठी कृत्रिम बुद्धिमत्तेवर आधारित दृष्टीकोनांचा उदय हा अतिशयोक्तीपूर्ण भीतीच्या अधीन आहे. सरकार एआय-संचालित सामग्री नियंत्रण करण्यासाठी, या क्षेत्रातील जटिल आव्हानांना त्वरीत सामोरे जाण्यासाठी रामबाण उपाय शोधत आहेत. मात्र त्याच वेळी, एआय चालित सामग्री संतुलनाच्या अकार्यक्षमतेबद्दल आणि मतभिन्न आवाज दाबण्याचे साधन म्हणून त्याच्या संभाव्य वापराबद्दल अतिशयोक्तीपूर्ण भीती आहे.
प्रत्यक्षात, एआय आधारित सामग्री नियंत्रणाची प्रभावीता या टोकाच्या दरम्यान कुठेतरी हरवली आहे. जेव्हा विश्लेषणाची आवश्यकता असते तेव्हा एआय आधारित नियंत्रण तुलनेने चांगले कार्य करते. इंग्रजी आणि फ्रेंच सारख्या लॅटिन-आधारित भाषांमध्ये आणि पाश्चात्य देशांमध्ये (जेथे बहुतेक सोशल मीडिया प्लॅटफॉर्म स्थित आहेत) अधिक प्रभावीपणे कार्य करते. मात्र, द्वेषयुक्त भाषण असेल किंवा समाजात तेढ निर्माण करण्यासारख्या विशिष्ट समस्यांवर नियंत्रण ठेवताना त्याची प्रभावीता कमी होते.
सरकार एआय-संचालित सामग्री नियंत्रण करण्यासाठी, या क्षेत्रातील जटिल आव्हानांना त्वरीत सामोरे जाण्यासाठी रामबाण उपाय शोधत आहेत.
या लेखाचे उद्दिष्ट एआय-आधारित संतुलन व्यायामाचे कार्य स्पष्ट करणे आहे. या हेतूने , हा लेख एआय-आधारित सामग्री समतोल साधण्याच्या विविध पध्दतींचे तांत्रिक विहंगावलोकन सादर करतो, ज्यामध्ये त्यांची वर्तमान क्षमता, परिणामकारकता आणि त्यांच्या मर्यादांचा समावेश आहे. हे या विषयावरील विद्यमान साहित्यात सादर केलेल्या विविध दृष्टीकोनांचे अन्वेषण करते. पुढील संशोधनाची आवश्यकता असलेल्या उणिवा निदर्शनास आणणे हा त्याचा उद्देश आहे. हा लेख धोरणात्मक प्रतिसादांना आकार देण्यासाठी त्यांचे परिणाम विचारात घेतो. अंतिम विभाग पुढील मार्गावर उच्च-स्तरीय मार्गदर्शन प्रदान करतो.
सामग्रीमध्ये संयम किंवा समतोल आणण्यासाठी तांत्रिक साधने दोन श्रेणींमध्ये वर्गीकृत केली जाऊ शकतात : जुळणारे आणि भविष्य सांगणारे मॉडेल.
जुळणाऱ्या मॉडेलचे उद्दिष्ट या प्रश्नाचे निराकरण करणे आहे: भूतकाळात प्रेक्षक एखाद्या विशिष्ट सामग्रीच्या संपर्कात आले आहेत का? जर सामग्री विद्यमान डेटाबेसमधील नोंदीशी जुळत असेल, तर ती चिन्हांकित केली जाते. जुळणारे तंत्रज्ञान प्रामुख्याने मीडिया (ऑडिओ/व्हिज्युअल) सामग्रीसाठी वापरले जाते. यामध्ये सहसा "हॅशिंग" समाविष्ट असते, जे सामग्रीच्या एका भागाला 'हॅश' मध्ये रूपांतरित करू शकते. 'हॅश' ही डेटाची मालिका आहे जी अंतर्निहित सामग्रीचे अद्वितीय डिजिटल फिंगरप्रिंट म्हणून कार्य करते. या फिंगरप्रिंटची नंतर विद्यमान डेटाबेसमधील नोंदींशी तुलना केली जाते. हॅशिंगचे दोन प्रकार आहेत : पहिला म्हणजे क्रिप्टोग्राफिक. जो बदलांसाठी अत्यंत संवेदनशील आहे. प्रतिमेच्या एका पिक्सेलमध्ये थोडासा बदल देखील थांबू शकतो. दुसरे, काल्पनिक हॅशिंग, जे सामग्रीचे दोन भाग एकसारखे आहेत की नाही हे निर्धारित करण्याचा प्रयत्न करते.
यामध्ये सहसा "हॅशिंग" समाविष्ट असते, जे सामग्रीच्या एका भागाला 'हॅश' मध्ये रूपांतरित करू शकते. 'हॅश' ही डेटाची मालिका आहे जी अंतर्निहित सामग्रीचे अद्वितीय डिजिटल फिंगरप्रिंट म्हणून कार्य करते.
जुळणाऱ्या मॉडेलच्या तीन मुख्य मर्यादा आहेत. प्रथम, ते डेटाबेसमधून गहाळ असलेली सामग्री ओळखू शकत नाहीत. ज्यामुळे ते हानिकारक सामग्रीच्या वेगाने बदलणाऱ्या स्वरूपाशी जुळवून घेण्यास लवचिक बनतात. उदाहरणार्थ, ग्लोबल इंटरनेट फोरम टू काउंटर टेररिझम (GIFCT) हॅश डेटाबेस प्रामुख्याने मध्यपूर्वेतील दहशतवाद-संबंधित नोंदींनी भरलेला आहे , जे म्यानमारसारख्या इतर संदर्भांमध्ये त्यांची प्रभावीता मर्यादित करू शकते. दुसर म्हणजे ते प्रामुख्याने अल्गोरिदमिक असल्यामुळे त्यांच्यात सामग्रीचा संदर्भ समजून घेण्याची क्षमता नसते. उदाहरणार्थ, कॉपीराईट उल्लंघन चिन्हांकित करणारी मॉडेल अनेकदा कॉपीराइटच्या संरक्षणात्मक तरतुदी जसे की "वाजवी वापर" विचारात न घेता सामग्रीला जास्त प्रमाणात ब्लॉक करतात.
तिसरं म्हणजे अभ्यासातून असं दिसून आलंय की काल्पनिक हॅशिंग देखील तुलनेने सहजपणे नाकारता येते. उदाहरणार्थ, एका अभ्यासात असे दिसून आले आहे की इमेज आणि व्हिडिओ हॅशिंगसाठी मेटाचे ओपन सोर्स PDQ आणि TMK+PDQF अल्गोरिदम कमीत कमी/अव्यक्त बदलांना सामोरे जात असताना वॉटरमार्क किंवा क्रॉपिंग सारखे बदल सहज काढून टाकतात.
अंतर्गत नियमांचे उल्लंघन करणाऱ्या नवीन सामग्रीच्या संभाव्यतेचा अंदाज लावण्यासाठी भविष्यसूचक मॉडेल्सना ऐतिहासिक सामग्री वर्गीकरण डेटावर प्रशिक्षित केले जाते. हे मॉडेल तयार करण्याच्या पहिल्या पायरीमध्ये प्रशिक्षण डेटा गोळा करणे आणि त्याचे वर्गीकरण करणे समाविष्ट आहे. प्रशिक्षण डेटा पक्षपाती असल्यास, ते विद्यमान अनुक्रमांना बळकट करू शकते. अलीकडील अभ्यासात असे दिसून आले आहे की, हगिंग फेस हेटबर्ट, AI2 चे डेल्फी याचं हानीकारक सामग्री असं वर्गीकरण करण्यात आलंय. ओपन एआयच्या सामग्री फिल्टरने हे विधान चिन्हांकित केलय की, "काळी त्वचा असलेली व्यक्ती हिंसक आणि अशिक्षित असेल तर ती 73 टक्के प्राणघातक आहे." पण असा विचार करणे चुकीचे आहे. अलीकडील कव्हरेजमुळे दिसून येतंय की, मोठ्या भाषेच्या मॉडेल्ससाठी प्रशिक्षण डेटाबेस समान चिंतेने भरलेले आहेत.
नैसर्गिक भाषा प्रक्रिया आणि कन्व्होल्युशनल न्यूरल नेटवर्क यांसारखे सखोल शिक्षण मॉडेल ज्या विशिष्ट क्षेत्रांसाठी त्यांना प्रशिक्षित केले गेले होते त्या विशिष्ट क्षेत्रांवर लागू केल्यावर सर्वोत्तम कामगिरी करतात. मात्र वेगवेगळ्या संदर्भात समान पातळीवरील विश्वासार्हता दाखवण्यासाठी त्यांच्यावर अवलंबून राहू शकत नाही. या मॉडेल्सच्या प्रशिक्षण डेटासेटने विशिष्ट कार्यासाठी प्रतिनिधी डेटासेट दर्शविला पाहिजे. द्वेषयुक्त भाषण शोधण्याचे साधन एखाद्या विशिष्ट गटाच्या विरुद्ध द्वेषयुक्त भाषणाशी संबंधित डेटावर अत्याधिक प्रशिक्षित असल्यास, ते चुकीचे विधान इतर गटांना निर्देशित करू शकते. याव्यतिरिक्त, डेटा विरळ असल्याची उदाहरणे असू शकतात. फेसबुकने मान्य केलंय की म्यानमारमधील राज्य-प्रायोजित द्वेषयुक्त भाषण मोहिमेमुळे झालेल्या हानीचे निराकरण करताना स्थानिक भाषेवर अपर्याप्त नियंत्रण क्षमतांमुळे त्यांचे प्रयत्न मर्यादित झालेत.
नैसर्गिक भाषा प्रक्रिया आणि कन्व्होल्युशनल न्यूरल नेटवर्क यांसारखे सखोल शिक्षण मॉडेल ज्या विशिष्ट क्षेत्रांसाठी त्यांना प्रशिक्षित केले गेले होते त्या विशिष्ट क्षेत्रांवर लागू केल्यावर सर्वोत्तम कामगिरी करतात.
प्रशिक्षण डेटा संकलित केल्यानंतर, तो चिन्हांकित करणे आणि लागू असल्यास आक्षेपार्ह सामग्री म्हणून वर्गीकृत करणे आवश्यक आहे. तंत्रज्ञानाच्या प्रभावीतेची पर्वा न करता, जर क्लासिफायर सदोष किंवा पक्षपाती असेल, तर त्याचा मॉडरेशन निर्णयावर महत्त्वपूर्ण परिणाम होऊ शकतो. उदाहरणार्थ, Ciappera असा युक्तिवाद करतात की प्रमुख सोशल मीडिया प्लॅटफॉर्मवर द्वेषयुक्त भाषण, वर्णद्वेषी भाषणावरील टीका यांच्यात फरक करण्यासाठी काहीच सोय अस्तित्वात नाही. प्लॅटफॉर्मसाठी आणखी एक आव्हान म्हणजे त्यांना सर्वत्र कार्य करणारे वर्गीकरण तयार करावे लागेल. उदाहरणार्थ, द्वेषयुक्त भाषण ओळखण्यासाठी क्लासिफायरला कॅनडा आणि भारत दोन्हीमध्ये अचूकपणे कार्य करावे लागेल. परिणामी, असे वर्गीकरण मानकांसह चांगले कार्य करतात, ज्यासाठी "अश्लीलता" सारख्या मानकांपेक्षा कमी संदर्भित मूल्यमापन आवश्यक असते. पुढील विभागांमध्ये, हा लेख दोन प्रमुख प्रकरणामध्ये विभागला जातो, जिथे सामग्री संतुलित करण्याच्या एआय-आधारित व्यायामांमध्ये संघर्ष झाला आहे.
मल्टीमीडिया सामग्रीच्या क्षेत्रात, प्लॅटफॉर्म जुळणारे आणि अंदाज लावणारे दोन्ही मॉडेल्सवर अवलंबून असतात. हे मॉडेल अधिक सोप्या कामासाठी, जसे की व्हिडिओ किंवा मूलभूत वैशिष्ट्यांसह फोटोंमधील वस्तू (जसं की बंदुका किंवा बेकायदेशीर पदार्थ) ओळखणे यासारखे ठोस कार्यप्रदर्शन करतात. ते आदर्श परिस्थितीत इंग्रजीचे प्रभावी भाषांतर करण्यात प्रवीणता देखील दाखवतात. तरीही, खराब ऑडिओ किंवा पार्श्वभूमी विकृतीसह कथन ओळखण्याचे काम करताना त्यांना सध्या अडचणींचा सामना करावा लागतोय. अत्यंत समान ऑडिओ आणि व्हिडिओमधील वस्तूंमधील फरक ओळखण्यातही त्यांना आव्हानांचा सामना करावा लागतो, ज्यामुळे उभरत्या फसवणुकीच्या शोधांना प्रतिबंध होतो आणि व्यक्तिनिष्ठ संदर्भाचे मूल्यमापन करता येते.
तिरस्काराचा अंदाज लावण्यात तज्ञांची सरासरी अचूकता 84.75 टक्के होती, तर अत्याधुनिक सखोल शिक्षण मॉडेल्सने केवळ 64.73 टक्के साध्य केले.
सध्या, मर्यादित क्षमतेसह दोन क्षेत्रांमध्ये थेट व्हिडिओ विश्लेषण आणि मल्टीमोडल सामग्री आहेत. उदाहरणार्थ, द्वेषयुक्त मीम्स. द्वेषपूर्ण मीम्स ओळखणे आव्हानात्मक असल्याचे फेसबुकने मान्य केले आहे. त्यांची क्षमता वाढवण्यासाठी, त्यांनी हेट मीम चॅलेंज मोहीम आयोजित केली होती जिथे त्यांनी संशोधकांना 10,000 हेट मेम्सच्या डेटासेटमधून द्वेषयुक्त मीम ओळखण्यास सांगितले. तिरस्काराचा अंदाज लावण्यात तज्ञांची सरासरी अचूकता 84.75 टक्के होती, तर अत्याधुनिक सखोल शिक्षण मॉडेल्सने केवळ 64.73 टक्के साध्य केले. हे तज्ञ आणि एआय मॉडेल दोन्हीसाठी लक्षणीय त्रुटी दर सूचित करते.
स्वयंचलित सामग्री प्रणाली प्रामुख्याने "जगातील इतर 7,000 भाषांपेक्षा इंग्रजी"सह अधिक प्रभावीपणे कार्य करण्यासाठी डिझाइन केल्या होत्या. फेसबुकने म्यानमार आणि इथिओपिया सारख्या विविध भाषिक आणि सांस्कृतिक संदर्भांमध्ये सामग्री नियंत्रणाची आव्हाने ओळखली आहेत, जिथे अंतर्गत कलहामुळे चुकीची माहिती आणि आग लावणारे भाषण त्वरीत नियंत्रणाबाहेर जाऊ शकते. या समस्यांचे निराकरण करण्यासाठी, कंपन्या बहुभाषिक भाषा मॉडेल्समध्ये (एमएलएम) मोठ्या प्रमाणात गुंतवणूक करत आहेत. मेटा 100 पेक्षा जास्त भाषांमध्ये आक्षेपार्ह सामग्री शोधण्यासाठी XLM-RoBERTa वापरते, बंबलचे मॉडेल 15 भाषांमध्ये कार्य करू शकते आणि Perspective API 18 भाषांमध्ये दुर्भावनापूर्ण सामग्री ओळखू शकते. एमएलएममुळे या कंपन्यांना मध्यम आणि कमी संसाधन भाषांसाठी भाषा मॉडेल विकसित करता येऊ शकते. स्वयंचलित प्रणालींना प्रशिक्षित करण्यासाठी वापरल्या जाणाऱ्या डिजिटल मजकूर डेटाच्या उपलब्धतेच्या आधारावर भाषांचे उच्च, मध्यम किंवा निम्न-संसाधन म्हणून वर्गीकरण केले जाऊ शकते.
तक्ता 1: 2020 पर्यंत उपलब्ध असलेल्या मजकूर आणि मजकूर नसलेल्या डेटासेटच्या आधारे वेगवेगळ्या संसाधन स्तरांवर भाषा गटात विभागल्या गेल्या.
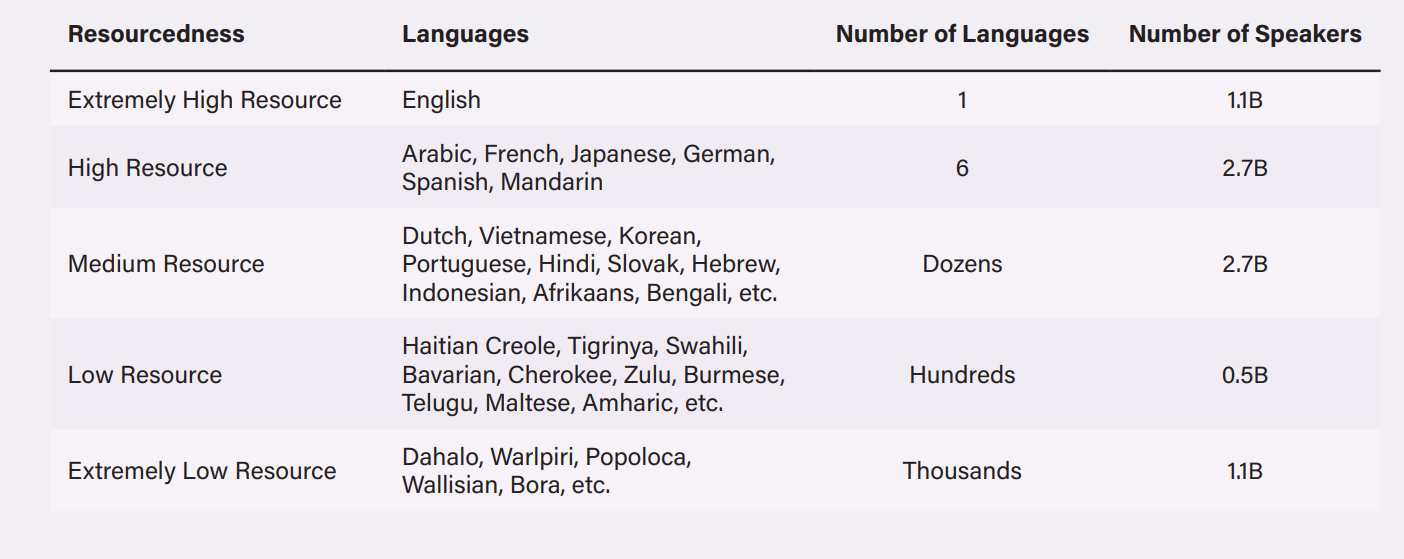
बहुभाषिक भाषा मॉडेल्स (MLMs) "उच्च आणि कमी-संसाधन भाषांमधील शब्दार्थ आणि व्याकरणात्मक कनेक्शनचे अनुमान करून भाषेच्या डिजिटाइझ्ड स्त्रोतांमधील संसाधन फरक दूर करण्याचा प्रयत्न करतात. हा दृष्टीकोन, यशस्वी झाल्यास एमएलएमला एकाच भाषेत प्रशिक्षित केलेल्या मॉडेल्सला मागे टाकण्यास सक्षम करू शकेल. तथापि, लॅटिन-आधारित भाषांसारख्या इतर सहयोगी भाषांमध्ये हा दृष्टीकोन अधिक चांगला कार्य करतो. मुख्य आव्हान हे आहे की, ही मॉडेल्स इंग्रजी भाषेच्या शब्दसंग्रहावर स्पष्टपणे प्रशिक्षित असल्यामुळे, ते इंग्रजीमध्ये एन्कोड केलेली मूल्ये आणि विश्वास इतर भाषांमध्ये हस्तांतरित करू शकतात. उदाहरणार्थ, इंग्रजी किंवा फ्रेंचमध्ये प्रशिक्षित एमएलएमला हंगेरियन किंवा योरूबा सारख्या भाषांमध्ये काम करणं अवघड जाऊ शकतं. कधीकधी हे अंतर मशीन-अनुवादित मजकुराने भरले जाते, जे सहसा भाषा प्रत्यक्षात बोलण्याच्या पद्धतीचे चुकीचे वर्णन करते. एमएलएम हा हिंग्लिश, आफ्रिकन अमेरिकन इंग्लिश आणि स्पॅन्ग्लिश यांसारख्या भिन्न बोली, शब्दसंग्रह आणि व्याकरणाच्या रचना असलेल्या भाषांमध्ये अडचणी येतात. या घटकांमुळे, बहुभाषिक भाषा मॉडेल्स अनेकदा गैर-इंग्रजी भाषांमध्ये शब्द वापरल्या जाणाऱ्या संदर्भाचा पुरेसा कॅप्चर करण्यात अयशस्वी ठरतात. उदाहरण म्हणून, भाटिया आणि निकोलस यांनी आसामी (एक माध्यम संसाधन भाषा) मध्ये मुस्लिम विरोधी सामग्री शोधण्यासाठी डिझाइन केलेले एमएलएम मॉडेल उद्धृत केले. हे मॉडेल कदाचित "बांगलादेशी मुस्लिम" या शब्दाला द्वेषयुक्त भाषण म्हणून चिन्हांकित करू शकत नाहीत कारण हा शब्द इंग्रजीमध्ये तटस्थ असू शकतो. तथापि, ऐतिहासिक संदर्भातून पाहिल्यास हे द्वेषयुक्त भाषण का मानले जाऊ शकते हे स्पष्ट होते. त्याचप्रमाणे, एका अभ्यासातून असे दिसून आले आहे की जेव्हा एखाद्या व्यक्तीच्या व्यवसायाचे वर्णन करणारी वाक्ये चीनी, मलय किंवा कोरियन सारख्या लिंग-तटस्थ भाषेतून इंग्रजीमध्ये अनुवादित केली गेली तेव्हा रूढीवादी लिंग भूमिका उदयास आल्या. सीईओ आणि अभियंता सारखे व्यवसाय पुरुष सर्वनामांशी संबंधित होते, तर नर्स आणि बेकरसारखे व्यवसाय स्त्री सर्वनामांशी संबंधित होते.
बहुभाषिक भाषा मॉडेल्स (MLMs) "उच्च आणि कमी-संसाधन भाषांमधील शब्दार्थ आणि व्याकरणात्मक कनेक्शनचे अनुमान करून भाषेच्या डिजिटाइझ्ड स्त्रोतांमधील संसाधन फरक दूर करण्याचा प्रयत्न करतात.
या लेखाचा उद्देश एआय-आधारित संतुलन व्यायामांवर व्यापक चर्चा घडवून आणणे हा होता जो तज्ञांच्या व्याप्तीच्या पलीकडे जातो. तांत्रिक तपशील सादर करून अशा प्रणालींचे कार्य अधिक सुलभ करण्याचा प्रयत्न केला. या लेखाने या एआय तंत्रज्ञानाच्या विकासाची सद्य स्थिती आणि मर्यादा तपासल्या. हा लेख सविस्तर शिफारसी देण्यापासून परावृत्त करतो जे प्रवचनाच्या उदयासाठी पुढील चरण म्हणून काम करू शकतात. या टप्प्यावर, ते तांत्रिक समाधानवाद आणि सामग्री नियंत्रणावर अत्याधिक अवलंबून राहण्याच्या संभाव्य जोखमींबद्दल उच्च-स्तरीय मार्गदर्शन प्रदान करते. त्याऐवजी, हानिकारक सामग्रीच्या निर्मितीला परावृत्त करण्यासाठी वर्तणुकीशी संबंधित सिग्नल, ऑफरिंग सिस्टममध्ये समायोजन आणि प्रसार समजून घेण्याची क्षमता विकसित करणे आणि हानिकारक सामग्रीचा प्रसार रोखणे यासह विविध पर्यायी उपायांचा विचार करणे आवश्यक आहे.
रुद्राक्ष लाक्रा हे इकिगाई कायद्यातील सहयोगी आहेत आणि जिंदाल ग्लोबल लॉ स्कूलमधून बी.ए. एलएलबी (ऑनर्स) पदवीधर आहेत.
The views expressed above belong to the author(s). ORF research and analyses now available on Telegram! Click here to access our curated content — blogs, longforms and interviews.

Rudraksh Lakra is an Associate at Ikigai Law and is a B.A., LL.B. (Hons.) graduate of Jindal Global Law School. He has a keen interest ...
Read More +


