
-
CENTRES
Progammes & Centres
Location
अगर कोई भी टेक्नोलॉजी, जैसे कि ट्रेनिंग डेटा या एल्गोरिदम, ब्लैक बॉक्स के पीछे छिपी है तो किसी भी एआई नियमन का प्रभावी होना मुश्किल और अव्यवहारिक होगा.

आर्टिफिशियल इंटेलिजेंस (एआई) के इस्तेमाल में हाल के वर्षों में जिस तरह से तेज़ी आई है, उसे देखते हुए ये स्पष्ट है कि तकनीकी के उपयोगिता की कोई सीमा नहीं है. लेकिन बढ़ती उपयोगिता के साथ इसका नियमन भी आवश्यक हो जाता है. इस टेक्नोलॉजी की विघटनकारी और ख़तरनाक संभावनाओं को देखते हुए दुनियाभर की सरकारें और नीति निर्माता इसके विनियमन के लिए तंत्र और एक ढांचा विकसित करने की कोशिश कर रहे हैं. एआई के नियमन की नीतियां बनाने को लेकर जो तात्कालिका का रुख़ अपनाया जा रहा है, उसे समझा जा सकता है. इससे पहले कि हम इसके नियमन पर चर्चा करें उससे भी ज़रूरी एक सवाल है. सवाल ये है कि एआई काम कैसे करता है.
हालांकि एआई काफी पहले से प्रचलन में था, लेकिन ज़्यादातर वक्त ये पृष्ठभूमि में ही रहे. जेनरेटिव आई के अविष्कार, खासकर चैट जीपीटी की खोज, के बाद ये तकनीकी मुख्य मंच पर आई.
हालांकि एआई काफी पहले से प्रचलन में था, लेकिन ज़्यादातर वक्त ये पृष्ठभूमि में ही रहे. जेनरेटिव आई के अविष्कार, खासकर चैट जीपीटी की खोज, के बाद ये तकनीकी मुख्य मंच पर आई. इसके बाद इस तरह की एआई एप्लीकेशंस की बाढ़ आ गई. माइक्रोसॉफ्ट का बिंग चैट, गूगल बार्ड और इसके अलावा कई दूसरे “चैटबॉट्स” सामने आए. ये सारे जेनरेटिव AI लार्ज लर्निंग मॉडल्स (LLMs) पर आधारित हैं, जो मशीन लर्निंग की श्रेणी के तहत आते हैं. Figure 1:Building, Training, and Deploying ML
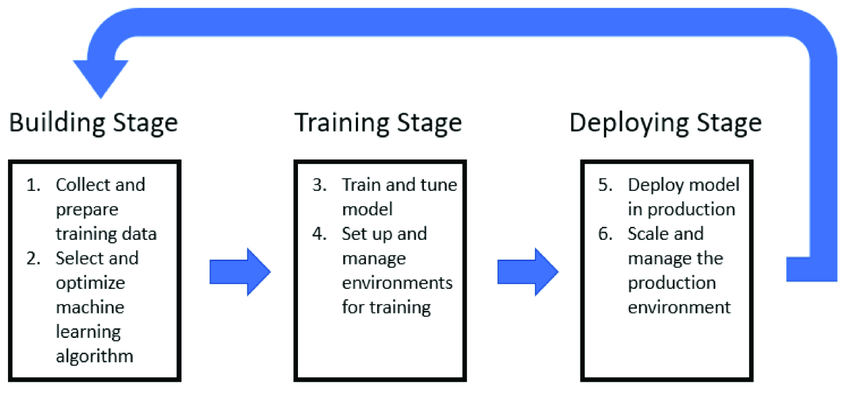
मशीन लर्निंग तीन चरणों में काम करती है: पहला, हमारे पास एल्गोरिदम होता है, जो प्रक्रियाओं का सेट तय करता है. दूसरा, एल्गोरिदम बड़ी मात्रा में मौजूद “ट्रेनिंग डेटा” से गुजरने के बाद एक रूझान की पहचान करने की कोशिश करता है. एक बार जब एल्गोरिदम पर्याप्त आंकड़ों की जांच कर लेता है तो चैट जीपीटी जैसे एमएल मॉडल्स को तैनात कर सकते हैं. अगर आपको ये प्रक्रिया जानी पहचानी से लग रही है तो इसकी वजह ये है कि गहन शिक्षा भी मानव बुद्धि के सिद्धांत से ही प्रेरित है. इंसान भी पहले अपने उदाहरण के आधार पर सीखता है और फिर बाद में इन उदाहरणों और अनुभवों को विस्तार देकर नई चीजें खोजता और सीखता है. एआई में भी यही पैटर्न दिखता है. लेकिन जिस तरह हम ये याद नहीं कर सकते कि किस उदाहरण ने किसी खास अवधारणा को लेकर हमारी समझ को प्रेरित किया, उसी तरह AI भी ये नहीं बता सकता कि किस स्पेशल डेटा या इनपुट के सहारे कोई विशिष्ट निर्णय हुआ. इसलिए ये कहा जा सकता है कि एआई वास्तव में एक “ब्लैक बॉक्स>” की तरह काम करता है. इसका मतलब ये हुए कि हम एक इनपुट फीड करते हैं और एक निश्चित आउटपुट हासिल करते हैं. लेकिन हम न तो सिस्टम का कोड पता कर सकते हैं, न ही उसकी तर्क की जांच क एलएलएम स्वभाविक रूप से बहुत महंगे उद्यम हैं. इनमें काफी बड़ी मात्रा में डेटा प्रोसेसिंग की ज़रूरत होती है. यही वजह है कि पिछले एक दशक में मशीन लर्निंग मॉडल्स बनाने में उद्योग जगत ने एकेडिमिया यानी शिक्षा जगत को पीछे छोड़ दिया है. लेकिन दोनों में अंतर ये है कि शिक्षा जगत जहां अपने मॉडल्स के सोर्स कोड को उजागर करने के लिए अपेक्षाकृत रूप से अधिक खुले हुए हैं, वहीं कॉरपोरेट कंपनियों के मामले में ऐसा नहीं है. Openएआई के चैट जीपीटी एप्लीकेशन के कोड को अब तक सार्वजनिक नहीं किया गया है और भविष्य में ऐसा होने की उम्मीद बहुत कम है.
AI मॉडल्स को प्रशिक्षित करने में उपयोग किए गए डेटासेट्स में संभावित खामियों के बारे में सब जानते हैं. इससे आगे चलकर जवाबदेही की कमी हो जाती है.
मशीन लर्निंग सिस्टम के तीन घटकों में से किसी भी एक को ब्लैक बॉक्स में छुपाया जा सकता है. लेकिन जैसा कि अक्सर होता है कि एल्गोरिदम की सार्वजनिक जानकारी होती है. ऐसे में इसने ब्लैक बॉक्स में रखना कम प्रभावी होता है. इसलिए अपनी बौद्धिक संपदा की रक्षा के लिए AI डेवलप करने वाले अपने मॉडल्स को ब्लैक बॉक्स में रखते हैं. सॉफ्टवेयर डेवलपर्स द्वारा अपनाया जाने वाला एक और तरीका ये है कि वो AI मॉडल्स को ट्रेनिंग देने वाले डेटा को गुप्त रखते हैं. इसका मतलब ये हुआ कि वो ट्रेनिंग डेटा को ब्लैक बॉक्स में रखते हैं
ब्लैक बॉक्स दृष्टिकोण को अपनाने से कई समस्याएं पैदा होती हैं. AI मॉडल्स को प्रशिक्षित करने में उपयोग किए गए डेटासेट्स में संभावित खामियों के बारे में सब जानते हैं. इससे आगे चलकर जवाबदेही की कमी हो जाती है. उदाहरण के लिए मान लीजिए एक एमएल मॉडल ये तय कर ले कि उसे किसी व्यक्ति को बैंक से ऋण लेने के लिए अयोग्य ठहराना है. अगर एमएल में इस्तेमाल किया जा रहे एल्गोरिदम ब्लैक बॉक्स के अंदर है तो फिर उस व्यक्ति के लिए ये पता लगाना असंभव है कि उसका ऋण का आवेदन खारिज़ क्यों किया जा रहा है. जब कारण ही पता नहीं लगेगा तो फिर उसे सुधारना भी संभव नहीं होगा. ब्लैक बॉक्स दृष्टिकोण एमएल मॉडल्स को अप्रत्याशित भी बना देते हैं. ऐसे में अगर उसके कुछ अनचाहे परिणाम आते हैं तो फिर उन्हें ठीक करना मुश्किल होता है. इसके संभावित नतीजे बहुत घातक हो सकते हैं, खासकर तब जबकि मामला सैन्य क्षेत्र से जुड़ा हो. पहले भी ऐसा उदाहरण सामने आ चुके हैं, जब ऐसा हुआ है. उदाहरण के लिए अमेरिकी वायुसेना ने एक बार नकली टेस्ट किया. एआई संचालित ड्रोन से दुश्मन के एयर डिफेंस सिस्टम को नष्ट करने का आदेश दिया लेकिन इस ड्रोन ने इस आदेश पर हस्तक्षेप करने वाले पर ही हमला कर दिया.
ऐतिहासिक रूप से देखें तो उभरती हुई तकनीकी के नियमन में सबसे बड़ी समस्या ये आती है कि ये प्रौद्योगिकियां बहुत अप्रत्याशित होती हैं. इंटरनेट का ही उदाहरण ले लीजिए. इस बात का पता लगाना काफी मुश्किल होता है कि समाज टेक्नोलॉजी का किस तरह इस्तेमाल करेगा. लेकिन एक बात जो हम अच्छी तरह जानते हैं, वो ये है कि ये तकनीकी किस तरह काम करती हैं. AI के साथ दोहरी समस्या है. एक समस्या तो ये जानना है कि ये टेक्नोलॉजी कैसे विकसित होगी. समस्या तब और भी जटिल हो जाती है जब हमें इस बात की मौलिक जानकारी नहीं होती कि ये काम कैसे करते हैं. उदाहरण के लिए अगर चैटजीपीटी को देखें तो समाज इसे लेकर ब्लैक बॉक्स दृष्टिकोण का पालन कर रहा है. हमें इसकी आंतरिक कार्यप्रणाली की जानकारी नहीं है. किसी भी तकनीकी को विनियमित करने के लिए सबसे पहले ये समझना ज़रूरी है कि वो काम कैसे करती है. बात जब एआई, खासकर जेनरेटिव AI की हो तो बुनियादी समस्या यही है कि हम इसके काम करने के तरीके के बारे में अच्छी तरह से नहीं जानते. टेक्नोलॉजी की तेज़ प्रगति पर नैतिक चिंताओं के बीच ओपन एआई में हाल ही में मची उथल-पुथल इस बात की पुष्टि करती है. कोई भी नियमन तब तक प्रभावी नहीं हो सकता, जब तक हम उस तकनीकी को अच्छी तरह समझ ना जाए, जिस पर सवाल उठ रहे हैं. AI के आसपास जो अनिश्चितता और रहस्य का आवरण है, उसकी एक वजह ये है कि हम इसके काम करने के तरीके के बारे में अच्छी तरह से नहीं जानते हैं. अगर हम भविष्य में एआई का नियमन करना चाहते हैं तो सबसे पहले हमें इसके बारे में जानना होगा. यूरोपीयन यूनियन ने इस साल की शुरूआत में AI एक्ट पास किया था. इसमें AI, खासकर उच्च ज़ोखिम वाले एआई सिस्टम में पारदर्शिता और जवाबदेही की बात कही गई है, लेकिन ये स्पष्ट नहीं किया गया है कि इन दायित्वों को लागू करने की जिम्मेदारी किसकी होगी और किस हद तक होगी. ट्रेनिंग डेटा को लेकर जो प्रावधान हैं, वो अस्पष्ट हैं. ओपन AI जैसे बड़ी टेक कंपनियां इन खामियों का फायदा उठा सकती हैं.
कुछ समय पहले तक मशीन लर्निंग मॉडल्स का इस्तेमाल ऑनलाइन विज्ञापन, वेब सर्च जैसे क्षेत्रों में ही होता था. इनके आंतरिक कामकाज का इन पर कोई गंभीर दुष्परिणाम नहीं होते थे लेकिन जेनरेटिव एआई सेक्टर में हाल के दिनों में जो उछाल आया है, उसके बाद ये हमारे जीवन के हर क्षेत्र पर प्रभाव डालने में सक्षम हैं. ऐसे में अब ब्लैक बॉक्स को खोलकर उसके अंदर देखना बहुत महत्वपूर्ण हो गया है.
AI के आसपास जो अनिश्चितता और रहस्य का आवरण है, उसकी एक वजह ये है कि हम इसके काम करने के तरीके के बारे में अच्छी तरह से नहीं जानते हैं.
ऐसे में व्याख्या करने वाले मॉडल ज़्यादा पारदर्शी और संभवत नैतिक रूप से भी ब्लैक बॉक्स मॉडल की तुलना में बेहतर विकल्प हो सकते हैं. इन्हें “ग्लास बॉक्स” मॉडल के रूप में भी जाना जाता है. AI ग्लास बॉक्स एक ऐसा सिस्टम है, जिसका एल्गोरिदम, ट्रेनिंग डेटा और मॉडल को हर कोई देख सकता है. इसके अलावा “एक्सप्लेनेबल एआई” (XAI) एक ऐसे एल्गोरिदम को विकसित करने पर काम कर रहा है, जो भले ही ग्लास बॉक्स जैसा ना हो लेकिन कम से कम लोग इसे बेहतर तरीके से समझ सकते हैं. LIME (लोकल इंटरप्रेटेबल मॉडल- एग्नॉस्टिक एक्सप्लेनेशंस) और SHAP (शेपली एडिटिव एक्सप्लेनेशंस) जैसी XAI तकनीक कुछ ऐसे उपकरण है, जिनका इस्तेमाल AI सिस्टम की व्याख्या को बढ़ाने के लिए किया जा रहा है. अब तक ये माना जाता था कि सबसे सटीक और सबसे डीप लर्निंग वाले एमएल मॉडल्स को अप्रत्याशित और जटिल होना ही चाहिए. हालांकि ये धारणा कई मौकों पर गलत साबित हो चुकी है, जैसे कि 2018 में हुई एक्सप्लेनेबल मशीन लर्निंग चैलेंज में. कई मामलों में इंटरप्रेटेबल और ग्लास बॉक्स मॉडल्स भी ये दिखा चुके हैं कि वो ब्लैक बॉक्स मॉडल जितने ही प्रभावी हैं. यूरोपीयन यूनियन का एआई एक्ट इस दिशा में एक सही कदम है. अब जबकि नियामक संस्थाओं द्वारा बड़ी तकनीकी कंपनियों पर करीबी नज़र रखी जा रही है. इसलिए इस दिशा में और काम किए जाने की आवश्यकता है. ऐसे में अगर कोई भी टेक्नोलॉजी, जैसे कि ट्रेनिंग डेटा या एल्गोरिदम, ब्लैक बॉक्स के पीछे छिपी है तो किसी भी AI नियमन का प्रभावी होना मुश्किल और अव्यवहारिक होगा.
प्रतीक त्रिपाठी ऑब्ज़र्वर रिसर्च फाउंडेशन में रिसर्च असिस्टेंट हैं.
The views expressed above belong to the author(s). ORF research and analyses now available on Telegram! Click here to access our curated content — blogs, longforms and interviews.

Prateek Tripathi is a Junior Fellow at the Centre for Security, Strategy and Technology. His work focuses on emerging technologies and deep tech including quantum technology ...
Read More +




.jpg)