
-
CENTRES
Progammes & Centres
Location

भारत में प्राथमिक और माध्यमिक स्कूल तक की शिक्षा नि:शुल्क और अनिवार्य होने के बावजूद 6 से 14 वर्ष के आयु वर्ग के लगभग 20 प्रतिशत बच्चे इसमें नदारद पाए जाते हैं. विश्लेषकों की ओर से इसके लिए विभिन्न कारण गिनाए जाते हैं. सभी को सार्वभौमिक बुनियादी शिक्षा उपलब्ध करवाने की प्रमुख चुनौतियों में स्कूल का, पहुंच के बाहर होना तथा शिक्षा को लेकर अनुपयुक्त माहौल जैसे मुख्य कारणों का समावेश है. इसी संदर्भ में भारत में आरंभिक शिक्षा प्रणाली के स्वास्थ्य की गणना करने वाला इंडेक्स एक महत्वपूर्ण माध्यम साबित हो सकता है. यह पेपर भारत के विभिन्न राज्य और केंद्र शासित प्रदेशों के परफॉरमेंस, इंफ्रास्ट्रक्चर और इक्विटी (PIE) इंडेक्स को तैयार करता है. PIE इंडेक्स 2020-21 में पंजाब, सर्वश्रेष्ठ कार्य करने वाला बड़ा राज्य पाया गया. इसके बाद केरल और तमिलनाडु का नंबर आया. छोटे राज्यों में सिक्किम और गोवा सर्वोच्च स्थान पर रहे, जबकि लक्षद्वीप, पुडुच्चेरी और चंडीगढ़ केंद्र शासित प्रदेशों में सर्वश्रेष्ठ प्रदर्शन करने वाले पाए गए.
एट्रीब्यूशन : तन्मय देवी, वंशिका सुराणा और रिया शाह, “THE PIE इंडेक्स 2020-21: भारत में प्राथमिक और माध्यमिक शिक्षा प्रणाली के स्वास्थ्य की गणना,” ओआरएफ ओकेशनल पेपर नंबर 359, जुलाई 2022, ऑब्जर्वर रिसर्च फाउंडेशन.
किसी भी देश की आर्थिक उन्नति में उसकी श्रम शक्ति को गुणवत्ता देने वाली शिक्षा ही सबसे अहम भूमिका अदा करती है. शिक्षा की वजह से ही बेहतर मानव पूंजी, विकास के अवसर और बेहतर मेहनताना सुनिश्चित होता है,[i] जिसकी वजह से उत्पादकता में उच्च स्तर की वृद्धि हासिल की जा सकती है. इन सभी का संबंध देश के विकास से है, जिसकी गणना सकल घरेलू उत्पाद (GDP).[ii] से की जाती है. इस बात के भी प्रमाण मिले हैं कि अच्छी शिक्षा की वजह से व्यक्तिगत और सामाजिक स्वास्थ्य भी बेहतर रहता है,[iii] और अपराध की दर में कमी आती है.[iv] अत: स्कूल में प्रवेश की दर को बढ़ाने के साथ ही शिक्षा की समग्र गुणवत्ता में सुधार भारत जैसे विकासशील देश की अर्थव्यवस्थाओं के लिए बेहद आवश्यक हो जाता है.
भारत में प्राथमिक और माध्यमिक स्कूल तक की शिक्षा नि:शुल्क और अनिवार्य होने के बावजूद 6 से 14 वर्ष के आयु वर्ग के 80 प्रतिशत बच्चे ही स्कूल जाते हैं.[v] इसके बावजूद स्कूल तक पहुंच को लेकर असामान्यताएं हैं. जो स्कूल जाते हैं, उनमें भी शैक्षणिक सामग्री और सीखने की अवस्था की विभिन्नताएं हैं, जो जाति, लिंग, सामाजिक श्रेणी और भौगोलिक स्थिति की वजह से तय होती है. 2020-21 में उपलब्ध आंकड़ों के अनुसार प्राथमिक स्कूल छोड़ने वाले बच्चों की दर एक प्रतिशत है, जबकि माध्यमिक स्कूल तक पहुंचते-पहुंचते यह दर बढ़कर 14 प्रतिशत से ज्यादा हो जाती है.[vi] कम आय वाले घरों के बच्चों को तो और ज्यादा चुनौतियों का सामना करना होता है. एनुअल स्टेटस ऑफ़ एजुकेशन रिपोर्ट (ASER) 2019,[vii] के अनुसार 26 ग्रामीण जिलों में हुए एक सर्वेक्षण में पाया गया कि पहली कक्षा के केवल 16 प्रतिशत बच्चों को ही तय किए गए विशेष स्तर तक पाठ पढ़ना आता था, जबकि 40 प्रतिशत बच्चों के पास अक्षर पहचानने की मूलभूत गुणवत्ता भी नहीं थी. इसमें भी केवल 41 प्रतिशत बच्चे दो अंकों की संख्या को पहचान पाए थे.
भारत में प्राथमिक और माध्यमिक स्कूल तक की शिक्षा नि:शुल्क और अनिवार्य होने के बावजूद 6 से 14 वर्ष के आयु वर्ग के 80 प्रतिशत बच्चे ही स्कूल जाते हैं. इसके बावजूद स्कूल तक पहुंच को लेकर असामान्यताएं हैं. जो स्कूल जाते हैं, उनमें भी शैक्षणिक सामग्री और सीखने की अवस्था की विभिन्नताएं हैं, जो जाति, लिंग, सामाजिक श्रेणी और भौगोलिक स्थिति की वजह से तय होती है.
सीखने के ठोस परिणामों पर आधारित शिक्षा प्रणाली के स्वास्थ्य की गणना करने वाला सूचकांक विभिन्न राज्यों के परिणामों की तुलना करने में अहम साधन साबित हो सकता है. चूंकि स्कूली शिक्षा समवर्ती सूची में शामिल विषय है, अत: राज्य स्तर पर शिक्षा प्रणाली में सुधार के लिए तैयार की जाने वाली नीतियां काफी महत्वपूर्ण हो जाती हैं. इसी कारण इस स्टडी का उद्देश्य सब-नेशनल एनालिसिस प्रस्तुत करना है.
इसके परिणाम भारत के स्कूली शिक्षा के परिवेश की विविधता और जटिलताओं को समाहित करते हुए राज्यों और गैर सरकारी सेवा प्रदाताओं को डेटा आधारित निर्णय लेने की महत्वपूर्ण जानकारी उपलब्ध कराएंगे. इसमें गुणवत्ता सुधार रणनीति तैयार होने के बाद बेहतर लक्ष्य निर्धारित करने का समावेश हो सकता है. सूचकांक का निर्माण परिणामों और प्रक्रियाओं दोनों के दृष्टिकोण से किया गया है. इसका उद्देश्य शैक्षणिक परिणामों को परफॉरमेंस, इंफ्रास्ट्रक्चर और इक्विटी की दृष्टि से अनुकूल करने में सहायता करना है, अत: इसे PIE इंडेक्स कहा गया है.
यूनाइटेड नेशंस डेवलपमेंट प्रोग्राम (UNDP) ने 1990 में एक बहुचर्चित एजुकेशन इंडेक्स बनाया था, जिसकी गणना स्कूली शिक्षा के अपेक्षित वर्षो [a] और स्कूली शिक्षा के औसत वर्षों के मध्यमान मूल्यों का उपयोग करके की गई थी. इसमें फाइनल इंडेक्स स्कूली शिक्षा के अपेक्षित और औसत वर्षो के मध्यमान का जियोमेट्रिक मध्यमान है. यह ह्यूमन डेवलपमेंट इंडेक्स (HDI).[b],[viii] बनाने में उपयोग किए जाने वाले तीन उप-सूचकांकों में से एक है.
UN एजुकेशनल, साइंटिफिक एंड कल्चरल आर्गेनाईजेशन (UNESCO) ने इंडीकेटर्स (निदेशक) को प्रतिनिधित्व के रूप में इस्तेमाल करते हुए एजुकेशन फॉर ऑल डेवलपमेंट इंडेक्स (EFA डेवलपमेंट इंडेक्स – EDI) भी विकसित किया है, EDI के वेरिएबल्स – प्राथमिक समायोजित शुद्ध नामांकन अनुपात (सार्वभौमिक प्राथमिक शिक्षा की गणना के लिए); 15 वर्षो से ऊपर के बच्चों में साक्षरता की दर (वयस्क साक्षरता की गणना के लिए), पांचवीं कक्षा तक शिक्षा प्रणाली में बने रहने की दर (शिक्षा की गुणवत्ता की गणना के लिए) और लिंग समानता इंडेक्स हैं.
इसका उपयोग 115 देशों के लिए किया गया और बाद में उन्हें उच्च, मध्यम और निचली श्रेणी में रखा गया.[ix] यह दोनों सूचकांक देशों को समग्र रूप में देखते हैं. अत: उनकी रैंकिंग देश विशेष की खासियत को नहीं दर्शाती है.
2013 में कल्याणकारी अर्थशास्त्री एंटोनियो विलार[x] ने आर्गेनाईजेशन फॉर इकनोमिक को-ऑपरेशन एंड डेवलपमेंट (OECD) की एक विश्वव्यापी स्टडी, प्रोग्राम फॉर इंटरनेशनल स्टूडेंट असेसमेंट (PISA) के डेटा का उपयोग कर एक और एजुकेशनल डेवलपमेंट इंडेक्स (EDI) को विकसित किया. इस सूचकांक में शैक्षणिक उपलब्धियों को लेकर बहुआयामी दृष्टिकोण अपनाया गया है, जिसमें तीन पहलुओं पर विचार किया गया. इसमें प्रदर्शन (भाषा और गणित), समान हिस्सा और गुणवत्ता का समावेश है. इन तीनों पहलुओं की सामान्य वैल्यूज का जियोमेट्रिक मध्यमान ही EDI है. इन तीन पहलुओं के साथ अंतिम सूचकांक के वितरण का OECD देशों के मध्यमान से समतुल्य विश्लेषण किया गया. इस स्टडी से पता चला कि EDI के माध्यम से जो रैंक हासिल की गई वह रैंक PISA के तहत मिले औसत स्कोर को ध्यान में रखकर मिली रैंकिंग से महत्वपूर्ण रूप से ज्यादा अलग नहीं थी. लेकिन इसकी वजह से विभिन्न देशों की शैक्षणिक प्रणालियों के महत्वपूर्ण पहलुओं को लेकर भिन्नताओं को उजगार जरूर कर दिया. उदाहरण के तौर पर यह साफ दिखाई दिया कि शिक्षा पर ज्यादा खर्च करने का अर्थ यह नहीं निकाला जा सकता कि इससे आपको बेहतर शैक्षणिक परिणाम मिलेंगे. 9
भारत में नीति आयोग के मार्गदर्शन में सामान्य वैल्यूज सेंट्रल स्क्वायर फाउंडेशन एंड कार्तिक मुरलीधरन ने 2019 में स्कूल एजुकेशन क्वालिटी इंडेक्स (SEQI) विकसित किया. इसमें सीखने, पहुंच, इंफ्रास्ट्रक्चर, इक्विटी और सरकारी प्रक्रियाओं के परिणामों का संज्ञान लिया गया था.[c] इस सूचकांक का उद्देश्य शिक्षा नीति की ताकत और कमजोरी की पहचान करना था, ताकि आवश्यकता पड़ने पर उसमें नीतिगत हस्तेक्षप से सहायता की जा सके. राज्यों को बड़े एवं छोटे राज्यों की श्रेणी में बांटा गया, जबकि केंद्र शासित प्रदेशों की तीसरी श्रेणी बनाई गई. इन श्रेणियों के तहत ही संकेतक मूल्यों को बढ़ाया गया, सामान्य किया गया और उसमें भार ओवरऑल परफॉरमेंस स्कोर एंड रैंकिंग तैयार की गई. हालांकि SEQI ने सीखने के परिणामों को समग्र माना और उदाहरण के तौर पर भाषा तथा गणित के बीच कोई स्पष्ट अंतर नहीं देखा गया. हालांकि 2013 में ही विलार ने यह दिखा दिया था कि यह अंतर एक विशेष शैक्षणिक प्रणाली की कमजोरी और ताकत को समझने के लिए बेहद महत्वपूर्ण होता है.[xi]
हाल ही में, 2020 में IIS जयपुर की अंजलि मीणा और अनिमा वैश्य ने 2016-17 के लिए डिस्ट्रिक्ट इनफार्मेशन सिस्टम फॉर एजुकेशन (DISE)[d] की ओर से संकलित किए गए आंकड़ों का उपयोग करते हुए भारत में शिक्षा के विकास की पड़ताल की थी. उनका सूचकांक कुल 22 संकेतकों, जिसमें पहुंच, बुनियादी ढांचे, शिक्षकों, परिणामों का समावेश था, का अध्ययन करने के बाद तैयार किया गया था. उनकी पद्धति PCA का उपयोग करती थी, ठीक वैसे, जैसे SEQI में किया गया था.
सीमित डेटा स्त्रोतों के कारण यह स्टडी छात्रों के सीखने के परिणामों पर विचार नहीं कर सकी थी. हालांकि, इस स्टडी ने दर्शाया कि अधिकांश राज्यों ने प्राथमिक शिक्षा की तुलना में उच्च माध्यमिक शिक्षा ज्यादा विकसित की थी. इस स्टडी ने पाया कि तमिलनाडु और पंजाब जैसे राज्यों के EDI स्कोर्स बिहार और अरुणाचल प्रदेश जैसे अन्य राज्यों की तुलना में उच्च थे. इस स्टडी के परिणामों ने PCA[xii] की उपयोगिता पर भी पुन: मुहर लगा दी.
भारत में नीति आयोग के मार्गदर्शन में सामान्य वैल्यूज सेंट्रल स्क्वायर फाउंडेशन एंड कार्तिक मुरलीधरन ने 2019 में स्कूल एजुकेशन क्वालिटी इंडेक्स (SEQI) विकसित किया. इसमें सीखने, पहुंच, इंफ्रास्ट्रक्चर, इक्विटी और सरकारी प्रक्रियाओं के परिणामों का संज्ञान लिया गया था. इस सूचकांक का उद्देश्य शिक्षा नीति की ताकत और कमजोरी की पहचान करना था
कुल मिलाकर, विलार (2013) द्वारा विकसित सूचकांक के उप-सूचकांक और कार्यप्रणाली ने उत्साहजनक परिणाम दिए. हालांकि स्कूल में दाखिले और स्कूलों के प्रकार या स्कूलों में मौजूद बुनियादी ढांचे जैसे वेरिएबल्स पर विचार नहीं किया गया. इसके अलावा, भारत को इस स्टडी में शामिल भी नहीं किया गया था. ऐसे में भारत के लिए इस तरह की एक स्टडी और उससे भी ज्यादा उसके राज्यों और केंद्र शासित प्रदेशों के लिए इस तरह की स्टडी किए जाने की ज्यादा आवश्यकता थी.
वर्तमान सूचकांक का विकास PCA का उपयोग करके किया गया था. इसके तहत सीखने के परिणामों जैसे वेरिएबल्स को शामिल किया गया था, जो अन्य शिक्षा सूचकांकों को विकसित करने में शामिल नहीं था. इस विश्लेषण के निष्कर्ष भारत को शिक्षा प्रणाली के स्वास्थ्य को मजबूत करने के लिए बनाई जा रही नीति के बारे में विशेष सिफारिशें करते हैं.
PIE इंडेक्स को तीन श्रेणियों के आधार पर तैयार किया गया : परफॉरमेंस (सीखने के परिणाम); इंफ्रास्ट्रक्चर और इक्विटी. इन उप-सूचकांकों की स्वतंत्र और व्यक्तिगत गणना कर उनके मूल्यों का उपयोग सूचकांक बनाने के लिए किया गया.
इस सूचकांक के लिए नेशनल कॉउन्सिल ऑफ़ एजुकेशनल रिसर्च एंड ट्रेनिंग (NCERT) की ओर से किए गए नेशनल अचीवमेंट सर्वे (NAS) 2021 और नेशनल इंस्टिट्यूट ऑफ़ एजुकेशनल प्लानिंग एंड एडमिनिस्ट्रेशन (NIEPA) की ओर से तैयार किए गए U-DISE फ़्लैश स्टेटिस्टिक्स (2020-21) से लिया गया था. NAS के डेटा का उपयोग प्रदर्शन और समान हिस्सेदारी उप-सूचकांक की गणना के लिए किया गया, जबकि बुनियादी ढांचे के उप-सूचकांक की गणना के लिए U-DISE के डेटा का उपयोग किया गया.
यह सर्वेक्षण सर्व शिक्षा अभियान (SSA) के तहत सरकारी और अनुदानित स्कूलों में शिक्षा के प्रारंभिक और माध्यमिक चरणों में छात्रों की सीखने की उपलब्धियों का निरीक्षण करने के लिए किया गया था. तीसरी, पांचवीं, आठवीं और दसवीं के विद्यार्थियों के मानकीकृत परीक्षण किए गए, उनके स्कूल के माहौल, सामाजिक-आर्थिक पृष्ठभूमि और शिक्षकों के प्रशिक्षण संबंधी निर्देशों की प्रणाली और योग्यता की जानकारी को भी एकत्रित किया गया. इसके परिणाम का भविष्य में शिक्षा में होने वाली प्रगति का मूल्यांकन करने के लिए आधार रेखा के रूप में उपयोग किया जा सकता है.[xiii]
U-DISE[xiv] मान्यता और गैर-मान्यता प्राप्त स्कूलों की वार्षिक गणना है, जिसमें 4,000 से अधिक वेरिएबल्स यानी कारकों पर डेटा की जानकारी दी जाती है. इसमें स्कूल के प्रोफाइल, बुनियादी ढांचे, सीखने और सिखाने की सामग्री-साहित्य, उपकरण, इन्सेंटिव, दाखिले और शिक्षकों पर डेटा एकत्रित किया जाता है. U-DISE की वैधता और विश्वसनीयता को क्लस्टर संसाधन केंद्रों, ब्लॉक संसाधन केंद्रों और जिला राज्य प्रबंधन सूचना प्रणाली (MIS) यूनिट्स के माध्यम से निरंतर जांच के साथ-साथ लगभग 5 प्रतिशत स्कूलों के सैंपलों की संभवत: थर्ड पार्टी की ओर से की गई जांच की सहायता से परखा और सुनिश्चित किया जाता है. U-DISE डेटाबेस, NIEPA, राज्यों और केंद्र शासित प्रदेश की सरकारों तथा केंद्रीय शिक्षा मंत्रालय के संयुक्त प्रयासों का परिणाम होता है.
इस पेपर का उद्देश्य भारत में राज्य स्तर पर प्राथमिक और माध्यमिक शिक्षा के स्वास्थ्य की गणना करने के लिए PIE इंडेक्स विकसित करना है, ताकि इसमें सुधार के लिए कुछ नीतियां प्रस्तावित की जा सकें.
PIE इंडेक्स के वेरिएबल्स
PIE इंडेक्स की गणना के लिए निम्नलिखित वेरिएबल्स का उपयोग किया गया.परफॉरमेंस इंडेक्स : यह छात्रों के सीखने के परिणामों को दर्शाता है.
वर्णनात्मक आंकड़े टेबल 1 में दिए गए हैं. उनका उपयोग प्रत्येक उप-सूचकांक की गणना करने, नमूने का सारांश प्रदान करने, सेंट्रल टेंडेंसी के मध्यमान की गणना के मानक तय करने और वेरिएबल्स की गणना (मानक विचलन) के उपायों को निर्धारित करने के लिए किया जाएगा. वैल्यू अर्थात मूल्य की रेंज भी उपलब्ध करवाई गई है, ताकि इस बात का निरीक्षण किया जा सके कि मूल्यों का अर्थ क्या दर्शाता है. हालांकि इन मूल्यों का उपयोग वास्तविक सूचकांक की गणना में सीधे तौर पर नहीं किया जाएगा, लेकिन यह डेटासेट में उपलब्ध कारकों के बारे में बुनियादी जानकारी प्रदान करने और कारक के बीच के संभावित संबंधों को उजागर करने में उपयोगी हैं.
टेबल 1.
वर्णनात्मक आंकड़े
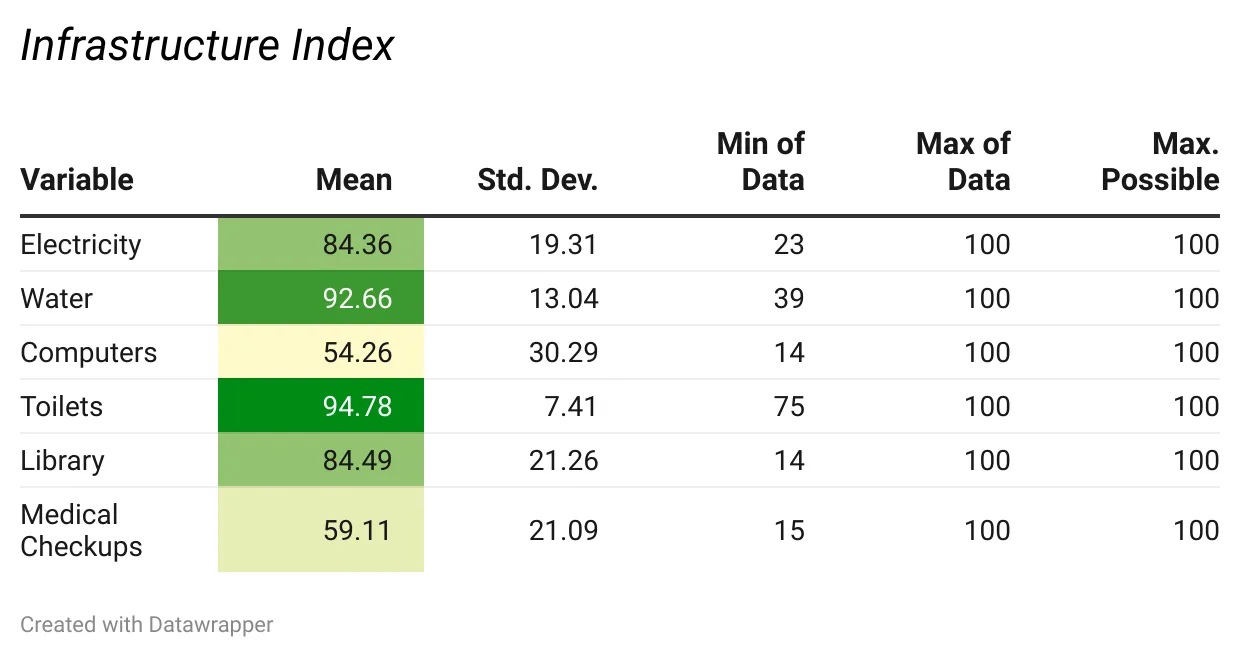
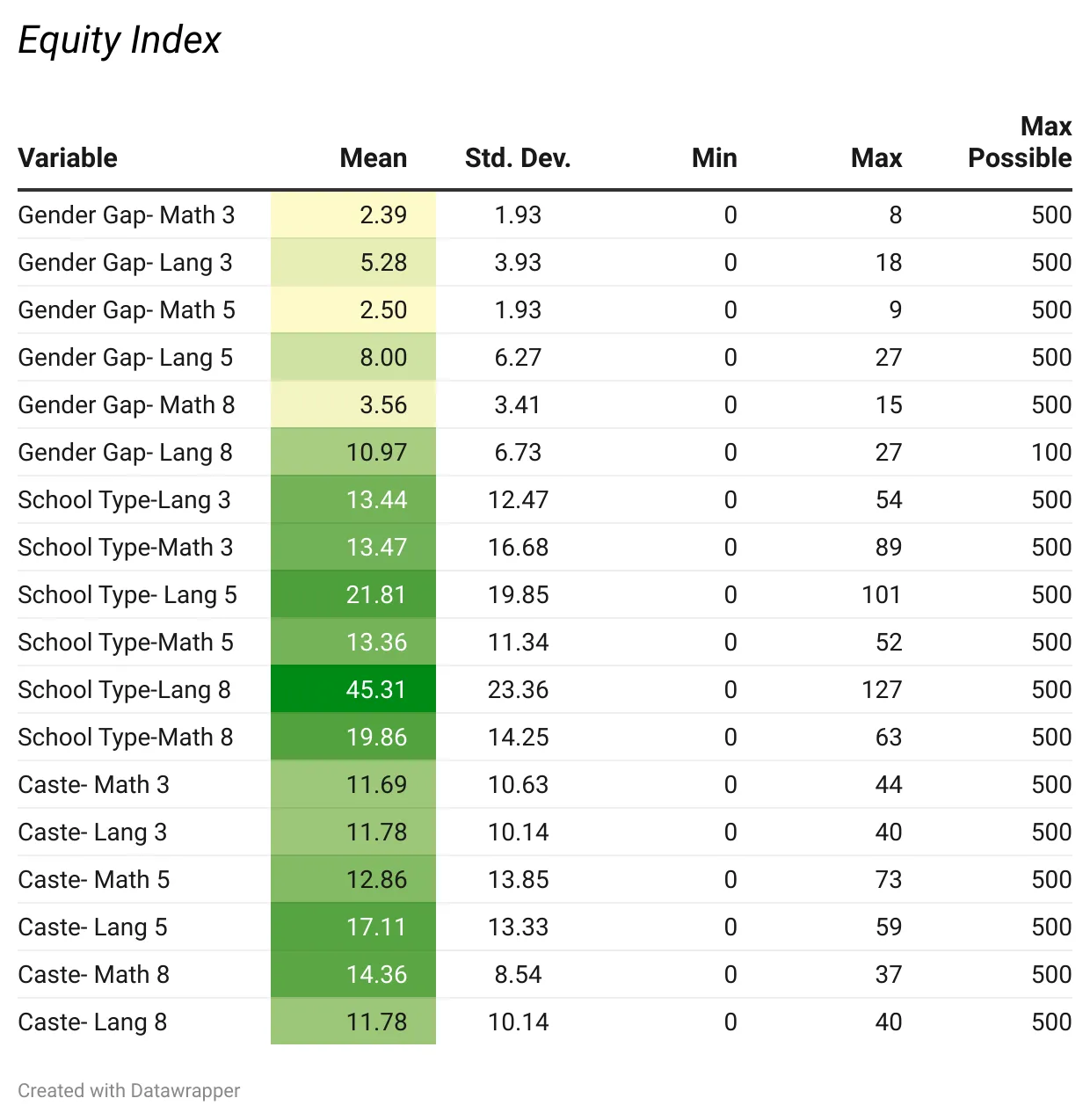
स्रोत: एनएएस 2021, यूडीआईएसई प्लस 2020-21; डेटारैपर के साथ बनाया गया.
कारकों के पैमाने में अंतर को ध्यान में रखते हुए, उन्हें नार्मलाइज्ड किया गया है, ताकि 0 से 1 तक समान श्रेणी सुनिश्चित की जा सके.
उप-सूचकांक
राज्य विशेष में स्कूलों के बुनियादी ढांचे का आकलन करने के लिए U-DISE डेटाबेस के वेरिएबल्स का उपयोग किया गया. प्रत्येक वेरिएबल् में राज्य विशेष के स्कूलों (पहली से आठवीं कक्षा) मे बुनियादी ढांचे के विशेष पहलू का प्रतिशत दर्ज किया गया. अधिकांश राज्यों के सभी स्कूलों में से लगभग 90 प्रतिशत स्कूलों में पुरुषों और महिलाओं के लिए अलग-अलग शौचालय, पीने का पानी और काम में आने लायक कक्षाएं मौजूद थीं. लेकिन 85 प्रतिशत के पास ही बिजली की सुविधा थी, जबकि 50 प्रतिशत के पास अच्छी तरह काम करने वाले कम्प्यूटर मौजूद थे. हां, त्रिपुरा जैसे कुछ राज्यों में केवल 20 प्रतिशत स्कूलों के पास बिजली मौजूद थी, जबकि बिहार और मेघालय जैसे राज्यों में अच्छी तरह काम करने वाले केवल 15 प्रतिशत कम्प्यूटर थे.
इक्विटी की गणना करने के लिए लेखकों ने आमतौर पर लिंग, स्कूल के प्रकार और जाति के आधार पर कमजोर समुदायों के सीखने के परिणामों में अंतर का संज्ञान लिया. इसकी गणना तीसरी, पांचवीं तथा आठवीं कक्षा के सभी लिंग, जाति और स्कूल की श्रेणी के विद्यार्थियों को भाषा और गणित में मिले अंकों के बीच अंतर को ध्यान में रखते हुए की गई. सीखने के परिणामों में अंतर को बच्चे की पृष्ठभूमि या जनसांख्यिकीय समूह की परवाह किए बिना संज्ञान में लिया गया कि सभी बच्चों को गुणवत्तापूर्ण शिक्षा मिलनी ही चाहिए, जो उनके शैक्षणिक प्रदर्शन में दिखाई दे.
यदि पृष्ठभूमि में अंतर मौजूद भी है, तो स्कूलों को सभी छात्रों को अपेक्षित स्तर तक लाने के लिए संसाधन उपलब्ध कराने में सक्षम होना चाहिए. लिंग के आधार पर प्रदर्शन में अंतर की पहचान करने के लिए लड़कियों और लड़कों के प्रदर्शन में अंतर पर विचार किया गया. इसी तरह लेखकों ने जाति के लिए अनुसूचित जाति/अनुसूचित जनजाति के छात्रों और सामान्य श्रेणी के छात्रों के प्रदर्शन में अंतर की गणना कर उस पर विचार किया.
(अनुसूचित जाति और अनुसूचित जनजाति की आबादी को U-DISE+ data से प्राप्त विभिन्न राज्यों में अनुमानित जनसंख्या अनुपात के आधार के हिसाब से महत्व दिया गया. उदाहरण के तौर पर सिक्किम में केवल पांच प्रतिशत आबादी अनुसूचित जाति की है, जबकि अनुसूचित जनजाति की आबादी 35 प्रतिशत है. अत: समूह के आकार में अंतर को ध्यान में रखते हुए अनुसूचित जाति के लिए 0.125 और अनुसूचित जनजाति के लिए 0.875 के हिसाब को महत्व दिया गया). अंत में, सार्वजनिक और निजी स्कूलों के बीच प्रदर्शन में अंतर को राज्य की ओर से प्रदान की जाने वाली नि:शुल्क शिक्षा और निजी स्कूलों की ओर से फीस लेकर दी जाने शिक्षा के परिणामों में अंतर को प्रतिबिंबित करने के लिए आधार माना गया.
मान्यताएं
सूचकांक के संचालन के लिए निम्न धारणाएँ बनाई गई है
win > 0 , where w= weight, i= name of the 3 sub-indices, n= position of weight
> 1, where N= number of variables, i= 3 sub-indices,
P, I, E >= 0, where P= परफॉरमेंस इंडेक्स , I= इंफ्रास्ट्रक्चर इंडेक्स , E= इक्विटी इंडेक्स
अंतिम सूचकांक तैयार करने के लिए पहले तीन उप-सूचकांक तैयार किए गए. लेखकों ने प्रत्येक उप-सूचकांक के सभी वेरिएबल्स के महत्व को समझने के लिए PCA का उपयोग किया. इसका मकसद यह था कि क्या डेटासेट में दी गई वेरिएबल्स की जानकारी मध्यमान से भिन्न है, और यदि भिन्न है तो किस हद तक भिन्न है. और यह भी देखा जा सके कि क्या उनके बीच कोई रिश्ता था. चूंकि वेरिएबल्स इस बिंदु से दृढ़ता से सहसंबद्ध हो सकते हैं कि वे निरर्थक डेटा उत्पन्न कर देते हैं. अत: यदि इन सब के बीच के संबंध है तो उसे खोजने के लिए एक कवरीयन्स मैट्रिक्स की गणना की गई.
प्रत्येक उप-सूचकांक के मुख्य कंपोनेंट्स के नए वेरिएबल्स को मूल वेरिएबल्स के एक रेखीय तरीके से संयोजित या मिश्रित करके तैयार किया गया था. मिश्रणों के बाद, नए वेरिएबल्स/मुख्य कंपोनेंट्स असंबद्ध थे, जिनमें मूल वेरिएबल्स की अधिकांश जानकारी समाहित हो गई थी. इस प्रकार n- डायमेंशनल डेटा से ‘n’ मुख्य कंपोनेंट्स मिले, लेकिन PCA पहले घटक में जितनी ज्यादा हो उतनी ज्यादा जानकारी और अंतिम में जितनी संभव हो उतनी कम जानकारी रखता है.
यह प्रक्रिया ऐजेन्वेक्टर्स और ऐजेन्वैल्यूज पर आधारित है, क्योंकि कवरीयन्स मैट्रिक्स के ऐजेन्वेक्टर्स के डारेक्शंस ऑफ़ द एक्सेस है जिसमें सबसे ज्यादा जानकारी अथवा मुख्य कंपोनेंट्स होते हैं. ऐजेन्वैल्यूज, ऐजेन्वेक्टर्स से जुड़े गुणांक हैं, जो यह निर्धारित करते हैं कि प्रत्येक प्रमुख घटक में कितनी भिन्नता भरी हुई है.
पीसीए में पहले चरण के रूप में, प्रत्येक घटक के लिए ऐजेन्वैल्यू की गणना की गई थी. फिर प्रत्येक उप-सूचकांक के लिए एक और उससे अधिक के ऐजेन्वैल्यू वाले घटकों का चयन किया गया. (एक से कम के ऐजेन्वैल्यू के साथ सभी घटकों को छोड़ देने की आदर्श परंपरा है, क्योंकि अधिकांश जानकारी 1 से ऊपर के ऐजेन्वैल्यू वाले घटकों को लेकर ही समझाई जाती है). इसके बाद, चयनित घटकों पर प्रत्येक वेरिएबल की लोडिंग वैल्यू की गणना की गई. प्रत्येक वेरिएबल का भार प्राप्त करने के लिए लोडिंग की समग्र वैल्यू को उसके संबंधित ऐजेन्वैल्यू से गुना किया गया था. PCA से लिए गए भार का उपयोग करके अंतिम उप-सूचकांक मूल्य की गणना की गई थी. प्रत्येक राज्य और केंद्र शासित प्रदेश के लिए तीन उप-सूचकांक की वैल्यूज प्राप्त करने के लिए यह प्रक्रिया प्रत्येक पर लागू की गई थी.
अंत में प्रत्येक उप-सूचकांक का भार पाने के लिए तीन उप-सूचकांकों के अंतिम मूल्यों पर PCA लागू किया गया था:
टेबल 2: PIE इंडेक्स भार
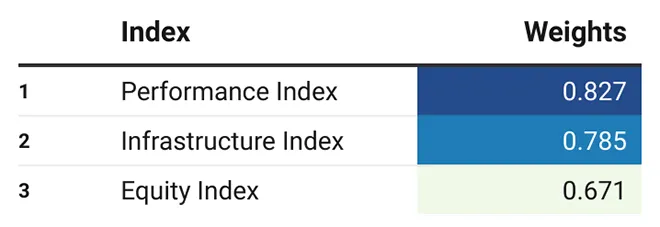
इसके बाद तीनों उप-सूचकांकों का भारित औसत लेकर PIE इंडेक्स की गणना करने के लिए भार का उपयोग किया गया.

इसके अलावा एक सूचकांक विकसित करने के लिए, जहां मूल्य इंगित करता है कि कोई राज्य अन्य राज्यों की तुलना में कैसा प्रदर्शन कर रहा है, PIE इंडेक्स के अंतिम मूल्यों को नॉर्मलाइज़्ड करने के लिए..
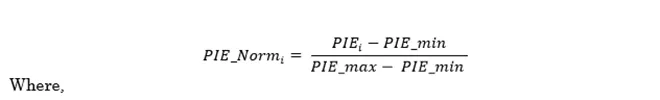
PIE_Normi = Normalized value of PIE इंडेक्स for state i
PIEi = Actual value of PIE इंडेक्स for state i
PIE_min = Minimum value of PIE इंडेक्स
PIE_max = Maximum value of PIE इंडेक्स
i = States and UTs in India
भारत में सभी राज्यों और केंद्र शासित प्रदेशों के PIE इंडेक्समें प्राप्त परिणाम नीचे दिए गए हीट मैप में दर्शाए गए हैं. इसे देखने पर साफ देखा जा सकता है कि विभिन्न क्षेत्रों में काफी महत्वपूर्ण भिन्नता है. एक गहरा रंग उच्च सूचकांक स्कोर अर्थात बेहतर प्रदर्शन का प्रतिनिधित्व करता है. पश्चिमी और दक्षिणी तट वाले राज्यों में एक गहरा पैच देखा जा सकता है, जो बेहतर प्रदर्शन का संकेतक है. पूर्व और उत्तर पूर्व में हल्के पैच होते हैं, जो खराब प्रदर्शन को दर्शाते हैं. पंजाब सबसे अच्छा प्रदर्शन करने वाला राज्य है, जबकि मेघालय का स्थान सबसे नीचे है.
Figure 1: PIE इंडेक्स – राज्यों में
स्त्रोत : स्वयं लेखकों का.
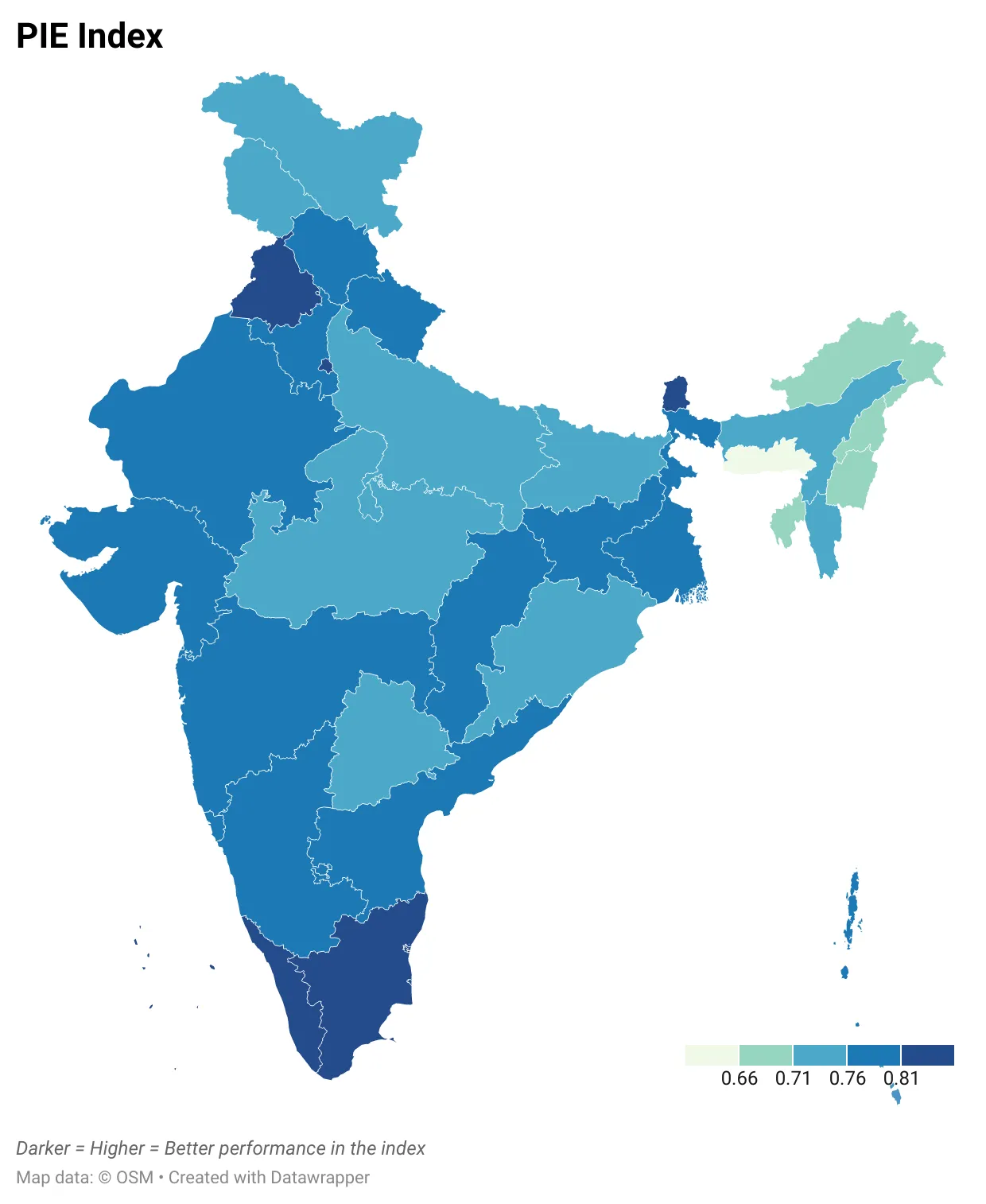
Source: Authors’ own
प्रत्येक राज्य के लिए फाइनल PIE इंडेक्स मूल्य और उप-सूचकांक के मूल्य, टेबल 3 में दिए गए हैं.
राज्यों और केंद्र शासित प्रदेशों को तीन श्रेणियों में विभाजित किया गया है: बड़े राज्य, छोटे राज्य और केंद्र शासित प्रदेश – यह इस तरह से सम-समान तुलना की अनुमति देता है.
टेबल 3: फाइनल PIE इंडेक्स वैल्यूज
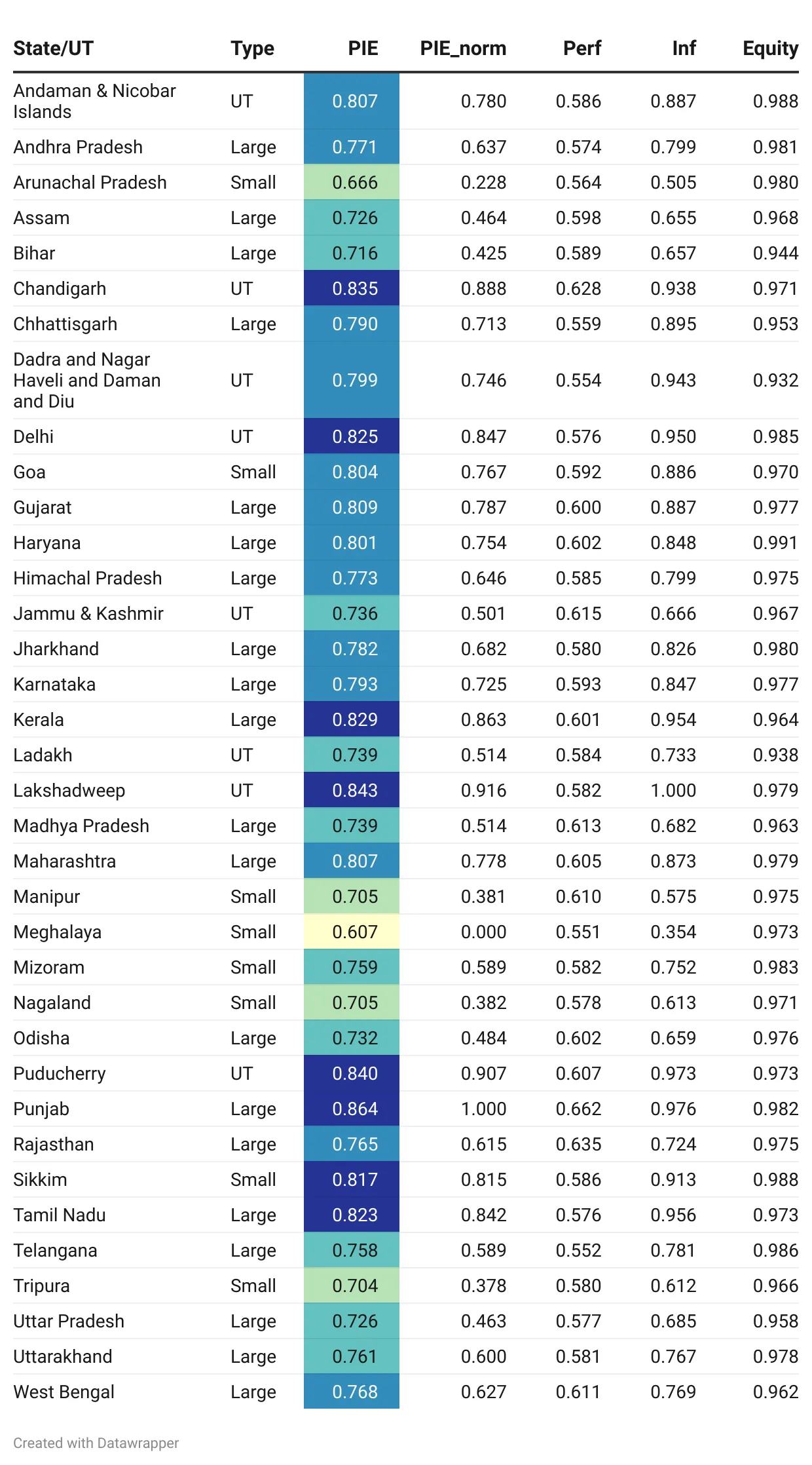
यहां डेटारैपर से बनाया गया टेबल है…
इसके अलावा चित्र 2 में संकेतक मूल्य प्रत्येक राज्य और केंद्र शासित प्रदेश के लिए सामान्यीकृत PIE वैल्यूज हैं. सामान्य तौर पर केंद्र शासित प्रदेशों ने सबसे अच्छा प्रदर्शन किया, जबकि छोटे राज्यों को सबसे नीचे का स्थान मिला. 2020-21 की रैंकिंग पर नजर डाली जाए तो यह देखा जा सकता है कि बड़े राज्य की श्रेणी में आने वाला पंजाब सबसे अच्छी रैंकिंग वाला राज्य था. पंजाब के बाद उस श्रेणी में केरल और तमिलनाडु का नंबर आता है. इसी प्रकार सबसे खराब प्रदर्शन करने वाले राज्यों में उत्तर प्रदेश और बिहार शामिल थे. अगर हम छोटे राज्यों की श्रेणी की बात करें तो इसमें सिक्किम और गोवा शीर्ष पर थे, जबकि मेघालय और अरुणाचल प्रदेश सबसे नीचे रहे. केंद्र शासित प्रदेशों की श्रेणी में लक्षद्वीप, पुडुचेरी और चंडीगढ़ ने शानदार प्रदर्शन किया.
चित्र 2: राज्य के आकार के अनुसार PIE सूचकांक
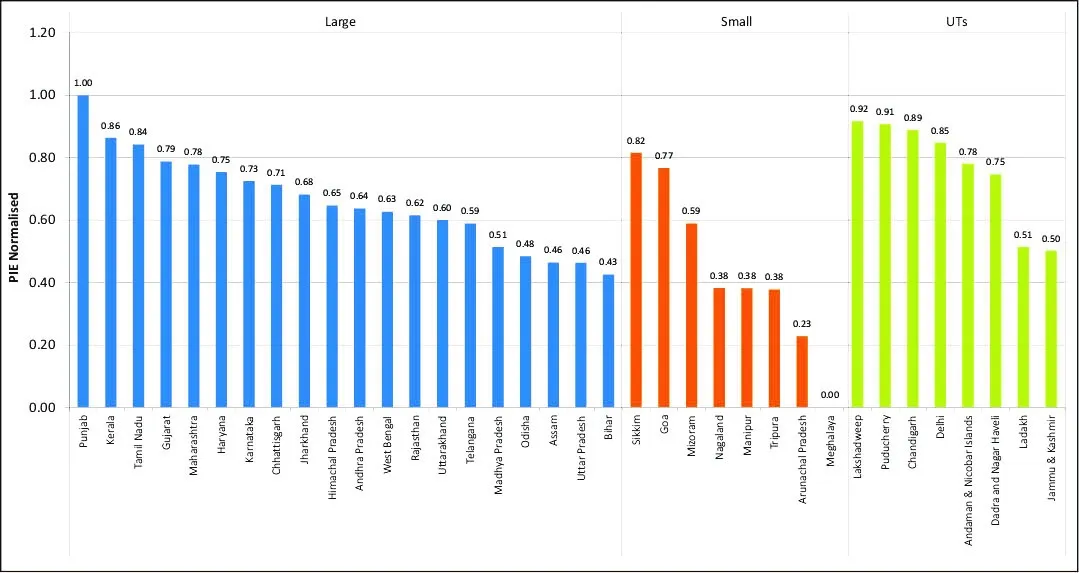
स्त्रोत : स्वयं लेखकों का
चित्र 3 सभी राज्यों और केंद्र शासित प्रदेशों के तीनों उप-सूचकांकों में किए गए प्रदर्शन को दर्शाता है. प्रदर्शन अंग्रेजी और गणित विषय सीखने के बाद मिलने वाला परिणाम है. इसमें पंजाब और राजस्थान प्रदर्शन उप-सूचकांक में शीर्ष प्रदर्शन करने वाले राज्यों के रूप में उभरे, जबकि तेलंगाना और मेघालय सबसे नीचे रहे. इंफ्रास्ट्रक्चर उप-सूचकांक में लक्षद्वीप और पंजाब सर्वोच्च स्थान पर हैं, जबकि अरुणाचल प्रदेश और मेघालय सबसे नीचे रहे. इक्विटी उप-सूचकांक में हरियाणा और सिक्किम का स्थान अव्वल रहा, जबकि लद्दाख, दादरा और नगर हवेली और दमन एवं दीव पिछड़े दिखाई दिए.
चित्र 3: PIE राज्यों में उप – सूचकांक
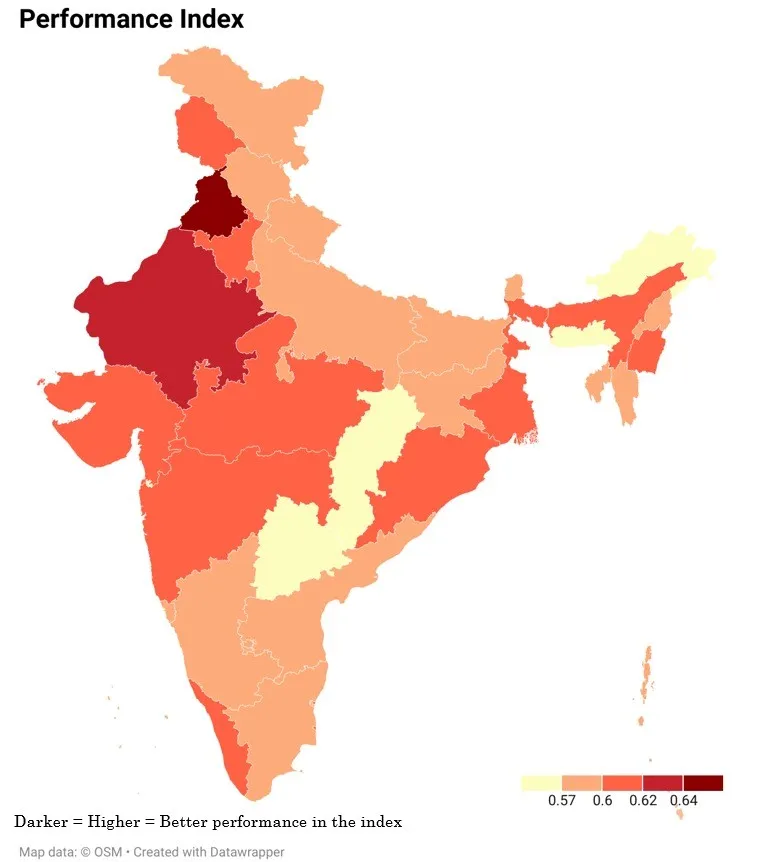
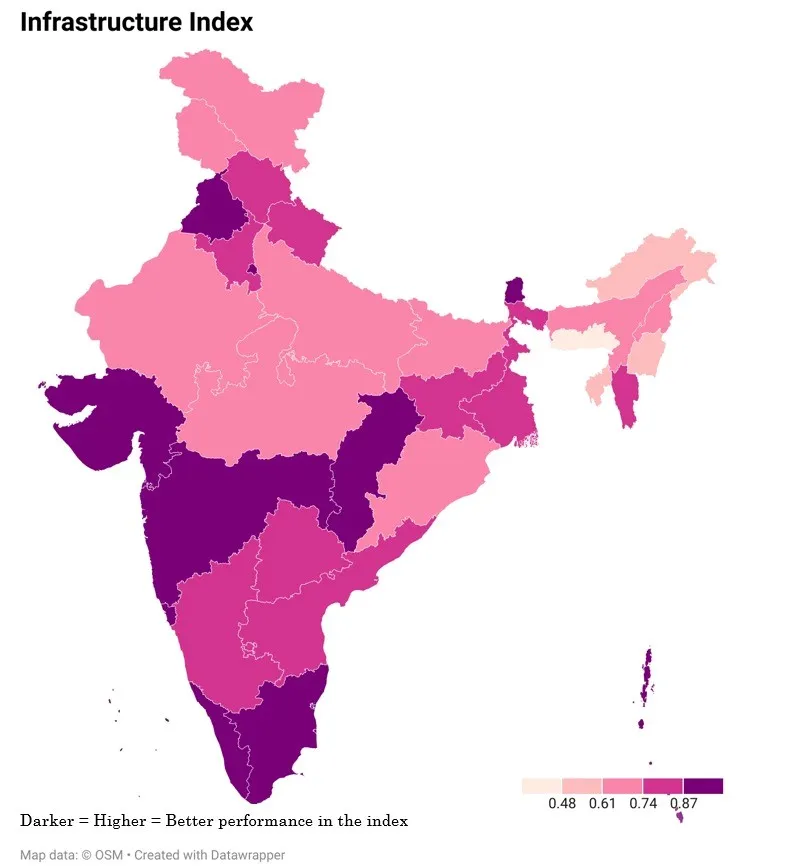
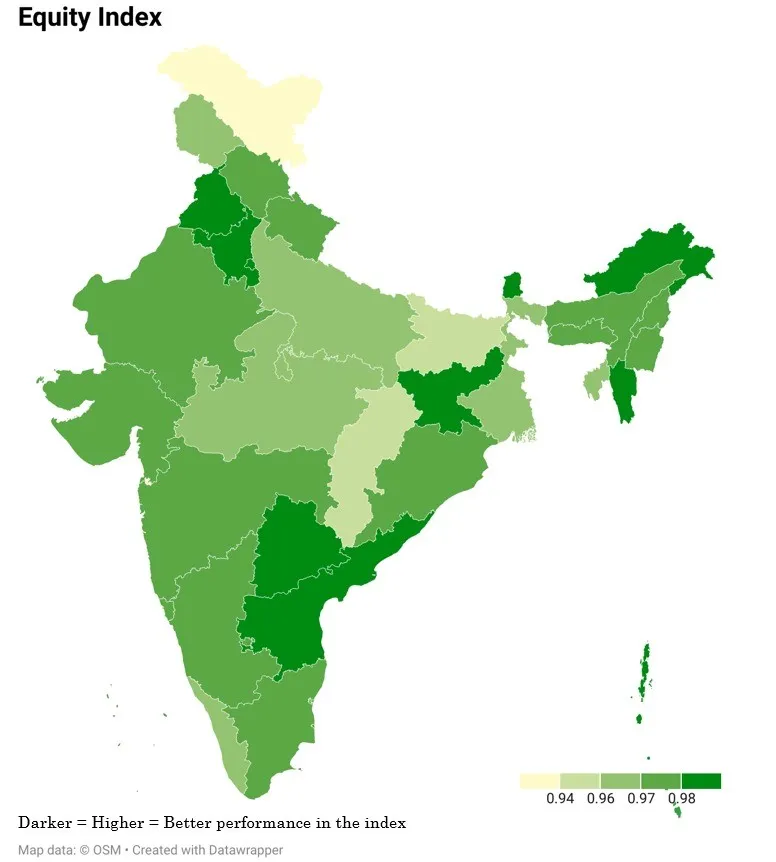
स्त्रोत : स्वयं लेखकों का
पंजाब जाति और लिंग के आधार पर लर्निंग के परिणामों, इंफ्रास्ट्रक्चर, और इक्विटी में प्राथमिक और माध्यमिक शिक्षा के लिए अग्रणी राज्य के रूप में उभरा. पंजाब के बाद 2011 की जनगणना के अनुसार, 93.91 प्रतिशत की उच्चतम साक्षरता दर वाले राज्य केरल का नंबर आता है. इस सूचकांक में साक्षरता सबसे लीडिंग अर्थार्त अग्रणी वेरिएबल्स है. इसमें बेहतरीन प्रदर्शन करने के बावजूद केरल, सूचकांक के अन्य वेरिएबल्स पर विचार किए जाने के बाद सूचकांक में दूसरे स्थान पर आता है. इसका कारण यह है कि पंजाब और राजस्थान जैसे राज्यों की तुलना में परफॉरमेंस और इक्विटी में उसका मूल्य अपेक्षाकृत कम होने के कारण हुआ है. इंफ्रास्ट्रक्चर के मामले में बड़े राज्यों में पंजाब, तमिलनाडु और केरल ने शानदार प्रदर्शन किया है. पिछले पांच दशकों में तमिलनाडु की साक्षरता दर दोगुनी से अधिक हो गई है. इसके विपरीत असम, बिहार और ओड़िशा जैसे राज्य काफी पिछड़ गए हैं. लर्निंग के परिणामों की बात करने पर पता चलता है कि छत्तीसगढ़ और तेलंगाना सबसे खराब प्रदर्शन करने वाले राज्य हैं.
पश्चिमी और दक्षिणी तट वाले राज्यों में एक गहरा पैच देखा जा सकता है, जो बेहतर प्रदर्शन का संकेतक है. पूर्व और उत्तर पूर्व में हल्के पैच होते हैं, जो खराब प्रदर्शन को दर्शाते हैं. पंजाब सबसे अच्छा प्रदर्शन करने वाला राज्य है, जबकि मेघालय का स्थान सबसे नीचे है.
छोटे राज्यों में, सिक्किम सबसे बेहतरीन प्रदर्शन करने वाला है, उसके बाद गोवा का नंबर आता है, जबकि पूर्वोत्तर में आने वाला मेघालय का स्थान सबसे नीचे है. सूचकांक के इंफ्रास्ट्रक्चर कंपोनेंट्स पर भी मेघालय सबसे कमजोर है. हालांकि लर्निंग के परिणामों की बात करें तो पूर्वोत्तर में ही आने वाले मणिपुर ने अन्य सभी छोटे राज्यों से बेहतर प्रदर्शन किया है. परफॉरमेंस सूचकांक की बात करें तो केंद्र शासित प्रदेशों में चंडीगढ़ और पुडुचेरी ने दूसरों से अच्छा प्रदर्शन किया है. इसी प्रकार सभी केंद्र शासित प्रदेशों में इंफ्रास्ट्रक्चर को ओवरआल इंडेक्स में एक परिभाषित विशेषता के रूप में देखा गया है. उत्तर प्रदेश, ओड़िशा और मणिपुर जैसे राज्यों ने इंफ्रास्ट्रक्चर की तुलना में परफॉरमेंस सूचकांक में बेहतर प्रदर्शन किया है. जैसा कि पहले ही दर्ज किया गया है कि पूर्वी और उत्तर-पूर्वी राज्यों की PIE इंडेक्स वैल्यू खराब है. Figure 3 दर्शाता है कि हालांकि वे राज्य परफॉरमेंस इंडेक्स पर तो अच्छा कर रहे हैं, लेकिन इंफ्रास्ट्रक्चर में पिछड़ गए हैं.
कुल मिलाकर, बड़े राज्य PIE इंडेक्स में छोटे राज्यों की तुलना में काफी बेहतर[xv] प्रदर्शन करते हैं. लेकिन केंद्र शासित प्रदेशों ने बड़े और छोटे दोनों राज्यों की तुलना में बेहतर प्रदर्शन करते हुए हायर इंडेक्स वैल्यू वाले समूह के रूप में उभरे है.[xvi] परफॉरमेंस इंडेक्स के पैमाने पर बड़े राज्यों में मध्यमान (औसत) सबसे अधिक और छोटे राज्यों में सबसे कम देखा गया है. जबकि केंद्र शासित प्रदेशों में अंतर सबसे अधिक देखा गया है. इंफ्रास्ट्रक्चर इंडेक्स में अंतर अन्य सब- इंडिकस की तुलना में बहुत अधिक है. इसका अर्थ है कि कुछ राज्यों ने इस पर बहुत अच्छा प्रदर्शन किया, जबकि अन्य का प्रदर्शन बेहद खराब रहा है. हालांकि, बुनियादी ढांचे के मामले में केंद्र शासित प्रदेश, छोटे और बड़े राज्यों को मुकाबले में काफी पीछे छोड़ रहे हैं. बुनियादी ढांचे में भारी अंतर की वजह से बुनियादी ढांचे के मामले छोटे राज्यों का स्कोर बेहद कम है. इक्विटी इंडेक्स में अन्य दो उप-सूचकांकों की तुलना में सबसे कम अंतर देखा गया. इसमें छोटे राज्यों में सबसे कम अंतर दिखाई दिया.
टेबल 4: PIE इंडेक्स के वर्णनात्मक आँकड़े
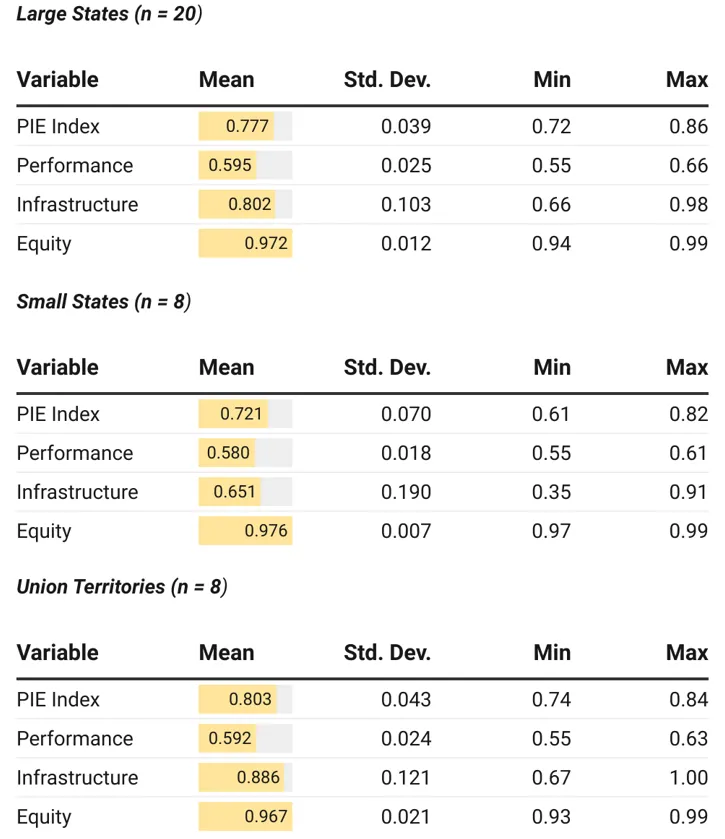
नॉर्मलाइज़्ड PIE इंडेक्स वैल्यूज के सहयोग से हम राज्यों की तुलना कर सकते हैं, जबकि ऐब्सोलेउट वैल्यूज से हमें शिक्षा प्रणाली के स्वास्थ्य को उसकी संपूर्णता में समझने में मदद मिलती है. राज्यों के आकार के आधार पर टेबल 5 न केवल औसत PIE इंडेक्स वैल्यूज दिखाती है, बल्कि इससे हम तीन उप-सूचकांकों का औसत मूल्य भी देख सकते हैं.
यह विश्लेषण राज्यों का साइज और टाइप में वर्गीकरण करने के अलावा उन्हें नॉर्मलाइज़्ड PIE इंडेक्स वैल्यूज के आधार पर पंचमक में भी डालता है. 0.8 से 1 के बीच इंडेक्स वैल्यू वाले सभी राज्यों को लेवल 1 के रूप में वर्गीकृत किया गया है, जबकि 0.2 से नीचे के सभी राज्यों को लेवल 5 में रखा गया. लेवल 1 और लेवल 2 में आने वाले राज्य बेहतर प्रदर्शन करने वाले हैं. इसी प्रकार लेवल 4 और लेवल 5 में आने वालों को अपनी शिक्षा प्रणालियों के स्वास्थ्य के लेकर चिंतित होना चाहिए. ऐसे राज्यों को प्रत्येक सब-इंडेक्स पर नजर डालकर यह देखना चाहिए कि वह ऐसे कौन से उपायों को प्राथमिकता दे सकते हैं, ताकि उनकी स्थिति में सुधार हो सके.
टेबल 5:स्तरों (Quintiles) में वर्गीकृत PIE इंडेक्स

स्रोत: स्वयं लेखकों का
PIE इंडेक्स से प्राप्त परिणामों की तुलना SEQI [e] से की गई है. 2016-17 से 2020-21 तक भारतीय शिक्षा की स्थिति में बदलाव को ट्रैक करने के लिए PIE इंडेक्स का उपयोग किया गया है. इस पर नजर दौड़ाने से यह साफ हो जाता है कि 2016-17 से 2020-21 से बड़े राज्यों की रैंकिंग तो अधिकतर समान ही रही है, निरंतर रही है, लेकिन छोटे राज्यों और केंद्र शासित प्रदेशों की रैंकिंग में लगातार बदलाव होता देखा गया है.
जैसा कि टेबल 6 में देखा जा सकता है, बड़े राज्यों की श्रेणी में आने वाले पंजाब ने अपनी रैंकिंग में ऊंची छलांग लगाते हुए SEQI इंडेक्स में नंबर 9 से PIE इंडेक्स में पहला स्थान हासिल किया है. ऐसा इसलिए संभव हो पाया क्योंकि उसने लर्निंग के परिणाम के साथ-साथ बुनियादी ढांचे में महत्वपूर्ण सुधार किया है. और इसका श्रेय शिक्षा सुधारों के क्षेत्र में किए गए कार्यान्वयन को दिया जा सकता है. पंजाब ने ‘पंजाब स्मार्ट कनेक्ट इनिशिएटिव’ अर्थात पंजाब स्मार्ट कनेक्ट पहल के तहत ‘स्मार्ट स्कूल’ नीति, ऑनलाइन शिक्षक स्थानांतरण नीति, ऑनलाइन शिक्षा और मुफ्त स्मार्टफोन वितरण को लागू करते हुए अपनी शिक्षा प्रणाली का पुनर्गठन किया. इसके विपरीत, ओड़िशा की रैंकिंग 2016-17 से 2020-21 तक काफी गिर गई.
टेबल 6: बड़े राज्यों की रैंकिंग : SEQI 2016-17 and PIE 2020-21
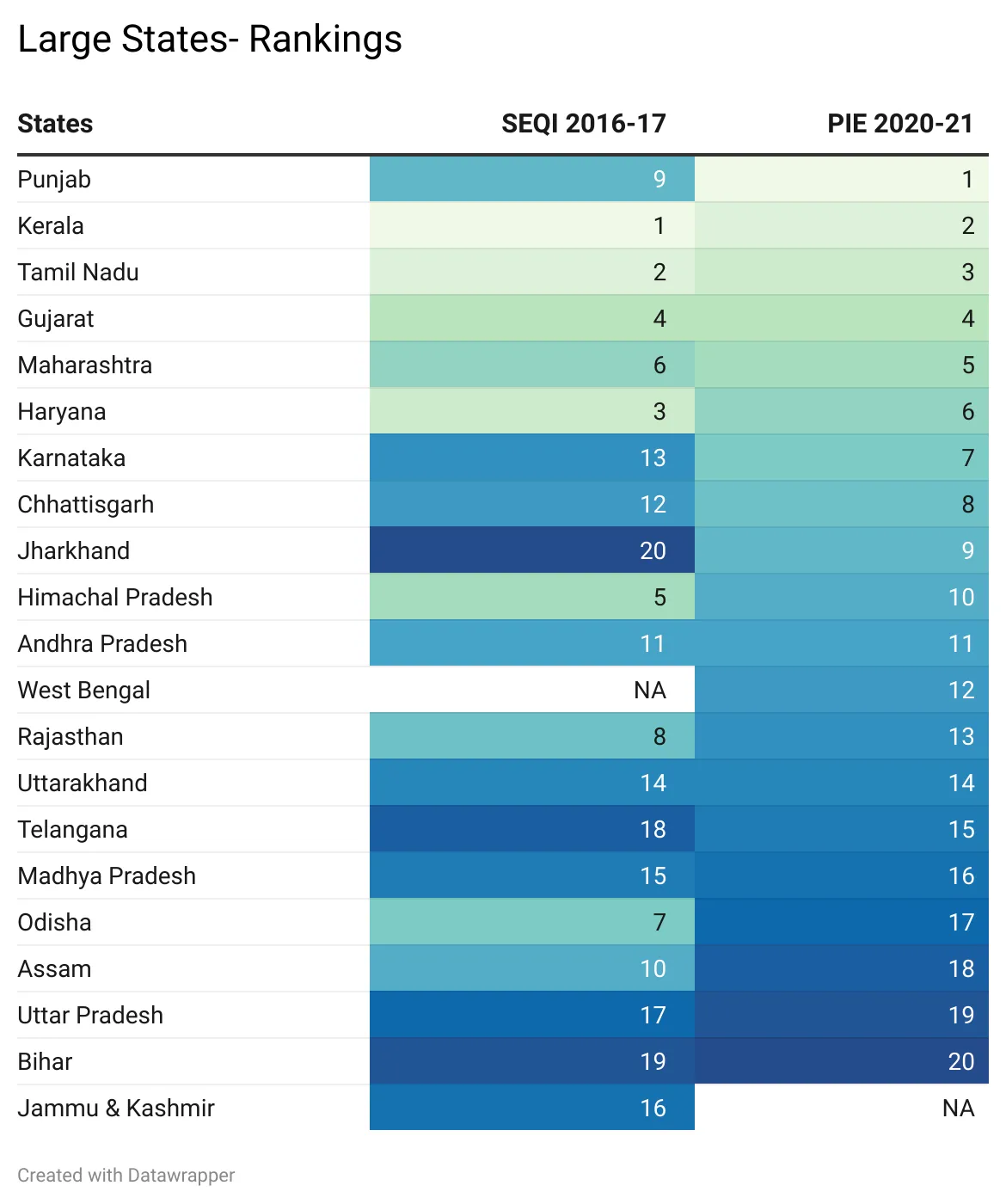
नोट: जम्मू और कश्मीर 2019 के बाद केंद्र शासित प्रदेशों की श्रेणी के अंतर्गत आता है.
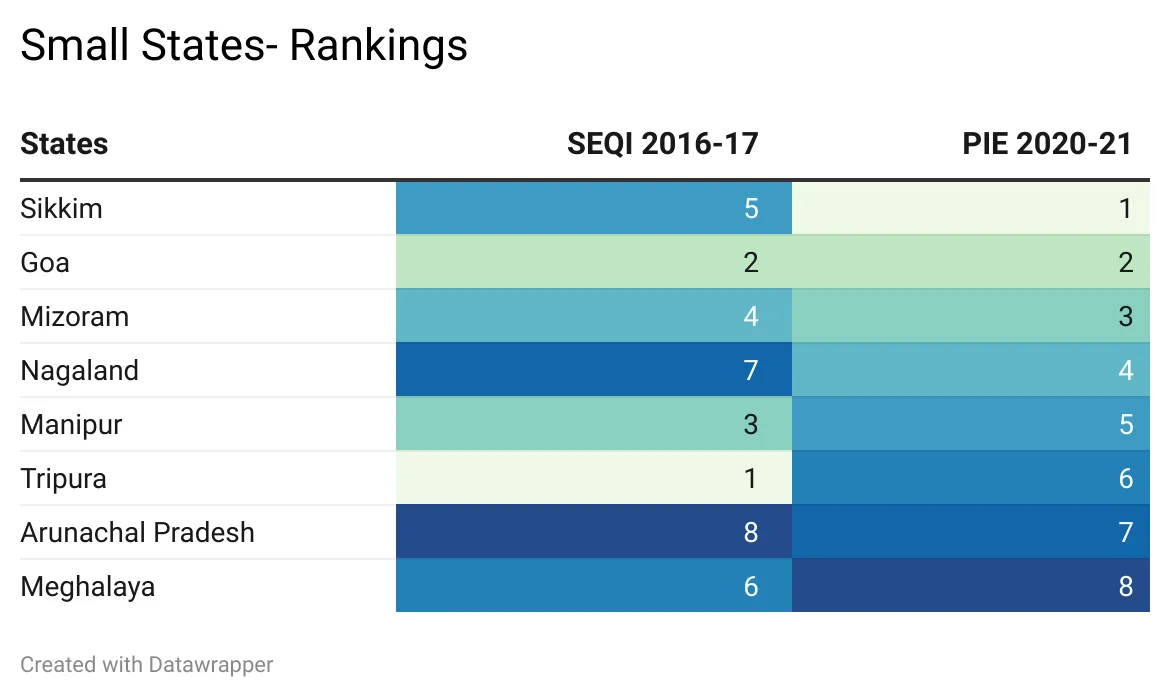
छोटे राज्यों में SEQI 2016-17 and PIE 2020-21 में काफी बदलाव अथवा अंतर देखा गया. बुनियादी ढांचे में व्यापक सुधार के साथ सिक्किम की रैंकिंग में काफी ऊपर चढ़ गया है और अब वहां की शिक्षा प्रणाली की तुलना गुजरात और महाराष्ट्र जैसे राज्यों से की जा सकती है.
टेबल 7: छोटे राज्यों की रैंकिंग : SEQI 2016-17 and PIE 2020-21
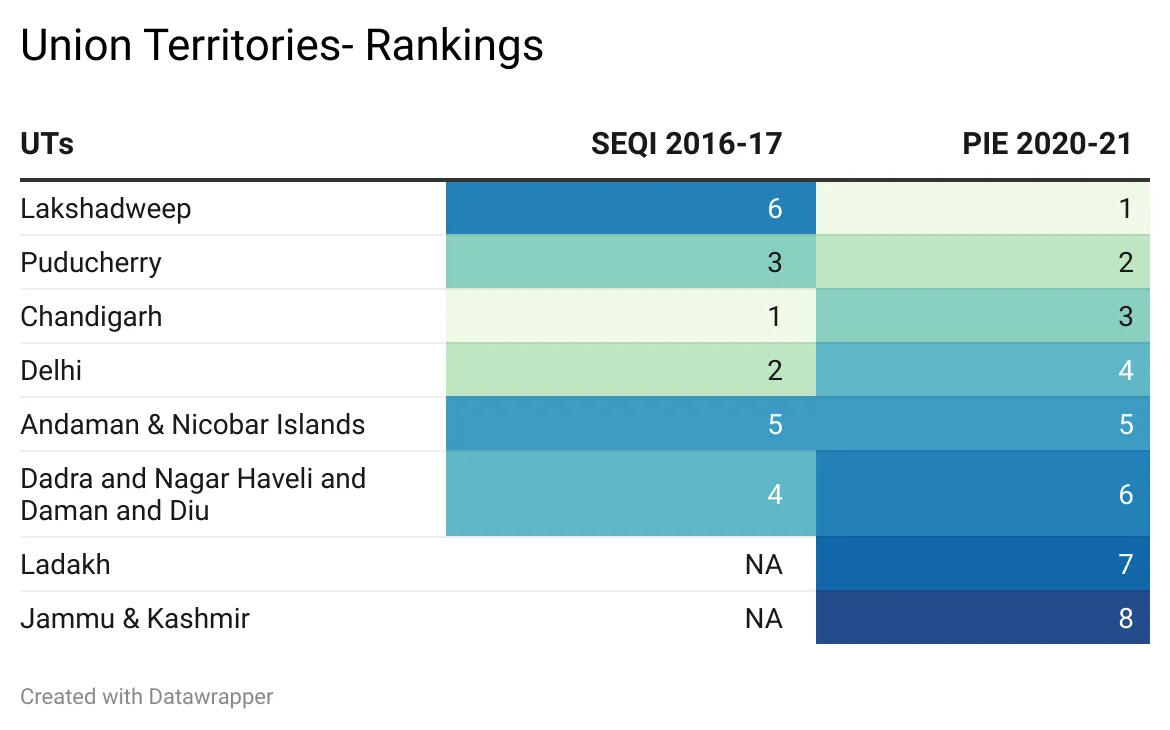
PIE इंडेक्स में केंद्र शासित प्रदेशों को छोटे और बड़े राज्यों की तुलना में बेहतरीन प्रदर्शन करने वाला पाया गया. लक्षद्वीप शीर्ष प्रदर्शन करने वाला बनकर उभरा है, लेकिन पुडुचेरी और चंडीगढ़ ने लर्निंग के परिणाम के मामले में लक्षद्वीप को पीछे छोड़ दिया है. बुनियादी ढांचे के मामले में सभी राज्यों और केंद्र शासित प्रदेशों की तुलना में लक्षद्वीप पहले नंबर पर है. इसका एक महत्वपूर्ण कारण यह है कि वहां स्कूलों की संख्या अपेक्षाकृत कम (लगभग 45 के आसपास) है. और संभवत: इसी वजह से इस बात की संभावना बढ़ जाती है कि वहां का प्रशासन उन्हें कम्प्यूटर, बिजली, पानी, शौचालय, पुस्तकालय और ऐसी अन्य सुविधाएं मुहैया करवाने में सफल होता है. PIE इंडेक्स में ध्यान देने वाली एक और बात यह है कि लक्षद्वीप, पुडुचेरी और चंडीगढ़ सभी एक दूसरे के बहुत करीब हैं. उनकी वैल्यूज क्रमश: 0.842, 0.840 और 0.835 है.
टेबल 8: केंद्र शासित प्रदेशो की रैंकिंग: SEQI 2016-17 and PIE 2020-21
PIE इंडेक्स हमें प्राथमिक और उच्च प्राथमिक शिक्षा (कक्षा पहली से आठवीं) तक की समग्र गुणवत्ता की पूरी परख करवाता है. राज्य और केंद्रशासित प्रदेशों के साथ-साथ इसके तीन उप-सूचकांकों द्वारा इसका पृथक्करण, हमें और आगे झांकने और समझने का अवसर प्रदान करता है. इस स्टडी पेपर के परिणाम राष्ट्रीय और राज्य स्तरों पर नीति निर्माण में उपयोगी साबित हो सकते हैं. उदाहरण के लिए, इसका निष्कर्ष यह है कि उत्तर-पूर्वी राज्यों में बुनियादी ढांचे को लेकर इंडेक्स वैल्यूज काफी कम हैं. अत: वहां के राज्यों में इस पर ध्यान केंद्रित करने और अधिक संसाधनों का आवंटन किए जाने की आवश्यकता है. छोटे राज्यों पर भी अतिरिक्त ध्यान दिया जाना चाहिए, क्योंकि वे सभी श्रेणियों- बड़े राज्यों, छोटे राज्यों और केंद्रशासित प्रदेशों में सबसे खराब प्रदर्शन करने वाले दिखाई देते हैं. PIE इंडेक्स 2020-21 में सबसे अच्छा प्रदर्शन करने वाले राज्य के रूप में पंजाब के उभरने को शिक्षा सुधारों के क्षेत्र में हुए बेहतरीन कार्यान्वयन से जोड़कर देखा जा सकता है. अत: अन्य राज्यों को भी उसके अनुभव से सबक लेने की आवश्यकता है.
इस स्टडी पेपर से पता चलता है कि भारत को एक मजबूत शिक्षा प्रणाली का निर्माण करने के लिए लर्निंग के परिणामों, इंफ्रास्ट्रक्चर और इक्विटी पर ध्यान देना बेहद आवश्यक है. राज्यों और केंद्र शासित प्रदेशों को निजी और सरकारी स्कूलों, लड़कों और लड़कियों की शिक्षा और कक्षाओं में जाति आधारित अंतर के बीच की खाई को पाटने की कोशिश करनी चाहिए. और अंत में सभी को यह सुनिश्चित करना होगा कि शिक्षा प्रत्येक व्यक्ति के लिए सुलभ बनाई जाए. शिक्षा का अधिकार कानून (RTE) जैसी नीतियों से लेकर सरकार ने शिक्षा को प्रोत्साहित करने वाले अनेक अभियानों से पहल की है, लेकिन उसे यह सुनिश्चित करना चाहिए कि किसी भी विद्यार्थी के साथ भेदभाव न हो. इसी प्रकार सकारात्मक कार्रवाई करते हुए सरकारों को यह देखना होगा कि छात्राएं और अन्य कमजोर वर्ग के लोग इससे वंचित और अछूते न रहें.
उम्मीद है कि राष्ट्रीय शिक्षा नीति (NEP), 2020, से शिक्षा के क्षेत्र में पर्याप्त सुधार होंगे. ऐसे में यह नीति लागू होने के बाद शिक्षा के क्षेत्र में आने वाला PIE इंडेक्स के माध्यम से परिलक्षित भी होगा. NEP ने एक ऐसा पाठ्यक्रम और अध्यापन कला में बदलाव का प्रस्ताव दिया है जिसके सहयोग से विद्यार्थियों में मजबूत शैक्षणिक क्षमताओं के साथ कम्प्यूटेशनल रीजनिंग और लॉजिकल थिंकिंग को स्थापित करने में सफलता मिलेगी. NEP में जो सबसे महत्वपूर्ण सुधार प्रस्तावित है वह यह कि वार्षिक परीक्षाओं का स्थान अब फॉउण्डेशनल असेसमेंट सिस्टम ले लेगा. इसमें यह भी सुझाव दिया गया है कि दसवीं कक्षा के विद्यार्थियों के लिए अब लो-स्टेक्स बोर्ड टेस्ट के साथ-साथ वर्ष के दौरान कई अन्य परीक्षाओं का भी आयोजन किया जाए.[xvii] इन सुधारों से देशभर में लर्निंग के परिणामों पर अनुकूल प्रभाव दिखाई दे सकता है.
सीखने के समग्र परिणामों में और सुधार उस वक्त होगा जब शिक्षकों के लिए पेशेवर तैयारी पर जोर दिया जाएगा. वर्तमान में प्रचलित और NEP की सिफारिशों के आधार पर विशेष रूप से कमजोर वर्गो में सीखने के परिणामों में अपेक्षित सुधार के लिए प्रौद्योगिकी का ज्यादा उपयोग किए जाने की संभावना देखी जा रही है. ऑनलाइन पाठ्यक्रमों के माध्यम से NEP पहुंच और समान हिस्सेदारी बढ़ाने की भी कोशिश कर रहा है, जिसका अंत में समान हिस्सेदारी के मुद्दे पर सकारात्मक प्रभाव पड़ेगा. ऐसे में आने वाले वर्षो में उन्नत शिक्षा के लिए डिजिटल इंफ्रास्ट्रक्चर पर नजर रखी जा सकती है.
इंडेक्स का निर्माण कुछ सीमाओं के तहत रहकर किया गया. इसके निर्माण के लिए आवश्यक जानकारी को दो अलग-अलग स्त्रोतों से हासिल किया गया. ऐसे में जानकारी एकत्रित करने की विधि में कुछ अंतर रहने की उम्मीद की जा सकती है.
प्राथमिक और माध्यमिक विद्यालयों में काफी भिन्नताएं होने की बात को स्वीकार कर भी लिया जाए तो भी दो स्वतंत्र PIE सूचकांक का निर्माण नहीं किया जा सकता. इसका कारण यह है कि प्राथमिक और माध्यमिक स्तर के स्कूलों के बुनियादी ढांचे को लेकर अलग-अलग जानकारी की उपलब्धता में कमी थी. अंत में PIE इंडेक्स, प्रक्रिया संचालित नहीं, बल्कि परिणाम-आधारित है. इसमें प्रशासनिक प्रक्रियाओं मसलन, विद्यार्थियों की उपस्थिति, शिक्षकों की उपलब्धता और पारिदर्शता जैसे कारकों पर विचार नहीं किया गया है.
NEP पर कार्यान्वयन होने के बाद PIE इंडेक्स को नए सिरे से तैयार किया जा सकता है. NEP के उद्देश्यों में आर्टिफीसियल इंटेलिजेंस और कोडिंग जैसे विषय हर बच्चे को सिखाना है, अत: अब सभी बच्चों को आरंभिक स्कूली वर्षो में कम्प्यूटर से अवगत होना होगा. ऐसे में इंफ्रास्ट्रक्चर सब-इंडेक्स में डिजिटल इंफ्रास्ट्रक्चर को भी एक वेरिएबल के रूप में शामिल करना भी उपयोगी साबित होगा. इसके अलावा NEP का उद्देश्य समग्र प्रगति रिपोर्ट तैयार करना भी है. अत: परफॉरमेंस सब-इंडेक्स को भी केवल अकादमिक क्षमताओं, भावनात्मक और बौद्धिक क्षमताओं तक ही सीमित न रखकर अपनी नजर समग्र प्रगति पर भी डालनी होगी, ताकि यह बात भी परफॉरमेंस सब-इंडेक्स में प्रतिबिंबित हो सके.
तन्मय देवी – अमेरिका के राइस यूनिवर्सिटी में इकॉनॉमिक्स में PhD की छात्र हैं.
वंशिका सुराणा – फ्लेम यूनिविर्सटी, पुणे से Applied Mathematics में स्नातक हैं.
रिया शाह – यू. एस. की ड्यूक यूनिवर्सिटी में Business Analytics मास्टर्स स्टूडेंट हैं.
इस इंडेक्स पर काम करने का अवसर देकर पूरी प्रक्रिया में उनका मार्गदर्शन करने के लिए लेखक फ्लेम यूनिवर्सिटी की प्रो. रेणु धड़वाल का आभार प्रकट करते हैं. वे इसमें अपने बहुमूल्य सुझाव देने के लिए फ्लेम यूनिवर्सिटी के प्रो. शिवकुमार जोलाड के भी आभारी हैं.
पूरक अंश
यह सूचकांक की विस्तृत कार्यप्रणाली पर चर्चा करता है.
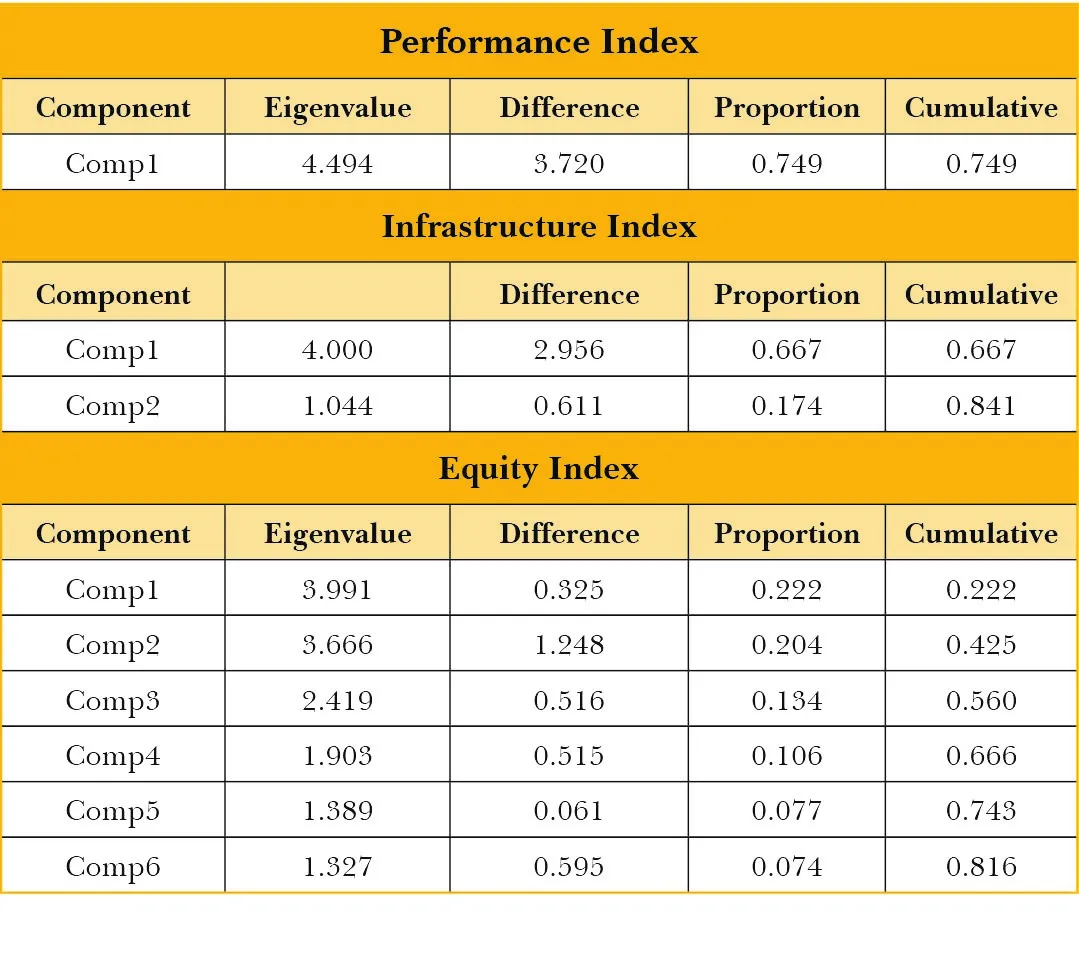
नीचे के टेबल उनके संबंधित उप-सूचकांकों के निर्माण में उपयोग किए गए प्रत्येक चयनित घटकों के लिए ऐजेन्वैल्यू को दर्शाते हैं. डिफरेंस कॉलम के तहत वर्तमान घटक के ऐजेन्वैल्यू और उसके बाद वाले के बीच अंतर की गणना की गई है. अनुपात कॉलम यह दर्शाता है कि प्रत्येक घटक द्वारा भिन्नता के अनुपात को कैसे समझा जाए. क्यूमिलेटिव अर्थात संचयी कॉलम इस अनुपात को संचयी तरीके से दर्शाता है. घटकों को हमेशा अलग किया गया और उनके ऐजेन्वैल्यू के अवरोही क्रम में क्रमबद्ध गया है.
उप-सूचकांकों की ऐजेन्वैल्यू
स्त्रोत : स्वयं लेखकों का.
परफॉरमेंस इंडेक्स में पहला घटक चुना जाता है, क्योंकि इसका ऐजेन्वैल्यू 1 से अधिक है. घटक 1 तक का संचयी वैल्यू 0.7491 है. इसका तात्पर्य यह है कि डेटा में 74.91 प्रतिशत भिन्नता को पहले दो घटकों की सहायता से समझाया जा रहा है. इसी तरह इंफ्रास्ट्रक्चर इंडेक्स में पहले दो घटकों का चयन किया गया है. यह आंकड़ों में 84.06 प्रतिशत भिन्नता की व्याख्या करते हैं. और आखिर में, पहले छह घटकों को इक्विटी इंडेक्स में चुनकर 81.64 प्रतिशत भिन्नता को समझाया जाता है.
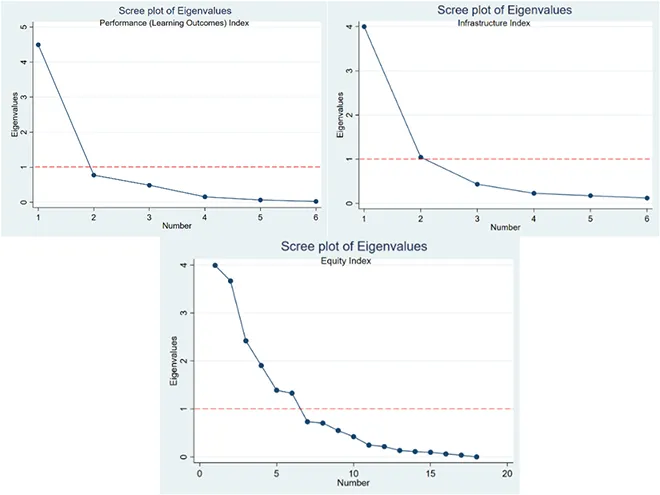
नीचे दिया गया फिगर सभी घटकों के ऐजेन्वैल्यू का सचित्र प्रतिनिधित्व करता है.
स्त्रोत : स्वयं लेखकों का.
तीन उप-सूचकांकों में से हर सूचकांक के लिए, संदर्भ रेखा के ऊपर स्थित बिंदुओं (घटकों का प्रतिनिधित्व) का चयन किया गया था. इसके बाद सभी चयनित घटकों पर प्रत्येक वेरिएबल के लोडिंग की गणना की गई. यह घटकों के साथ मूल वेरिएबल्स के सहसंबंध का प्रतिनिधित्व करता हैं. नीचे दिया गया ग्राफ पहले दो घटकों पर प्रत्येक वेरिएबल के लोडिंग की कल्पना को दर्शाता है.
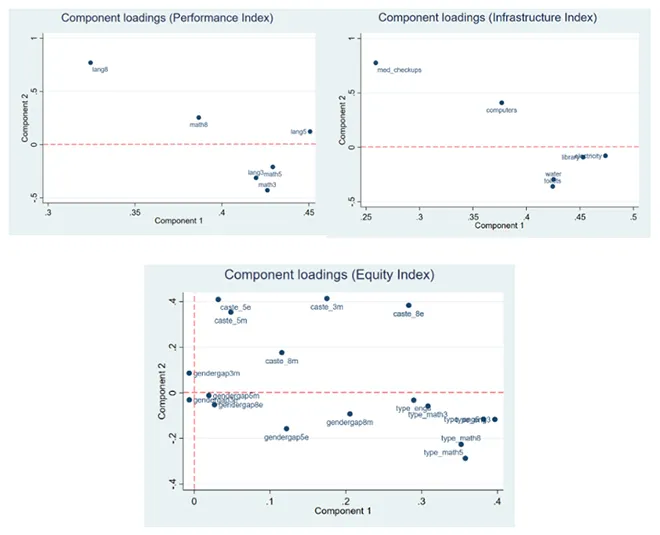
यह सुनिश्चित करने के लिए कि सूचकांक मजबूत है, इस पर कैसर-मेयर-ओल्किन (KMO) परीक्षण लागू किया गया. इस परीक्षण ने इस बात की पुष्टि की कि यह डेटा, प्रमुख घटक विश्लेषण के लिए उचित था. यह मूल्यांकन वेरिएबल के प्रत्येक सैम्पल के साथ-साथ पूरे मॉडल की पर्याप्तता का आकलन करता है. यह स्टेटिस्टिक्स वेरिएबल्स के बीच सामान्य वेरिएंस के अनुपात का एक माप है[xviii] के उपयोग को उचित ठहराने के लिए 0.5 से अधिक या उसके बराबर KMO होने का निष्कर्ष निकालना मानक अभ्यास है.
PIE इंडेक्स के लिए KMO परीक्षण के परिणाम इस प्रकार थे:
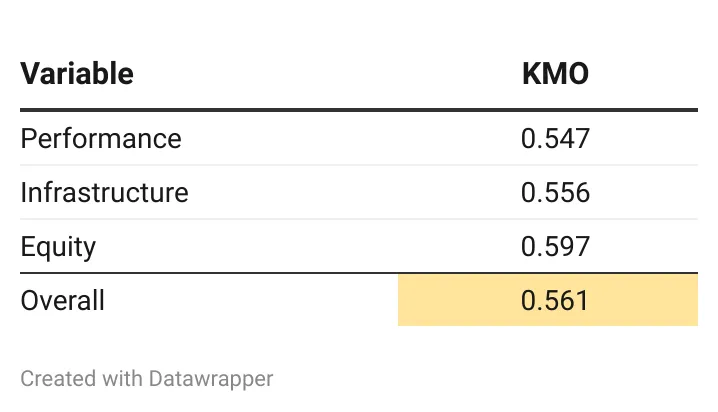
कैसर-मेयर-ओल्किन (KMO) नमूनाकरण पर्याप्तता (सैम्पलिंग एडिक्वेसी)
PIE इंडेक्स के परिणाम बताते हैं कि सभी वेरिएबल्स का केएमओ 0.5 से अधिक है. अत: एक मजबूत PIE इंडेक्स के निर्माण में PCA के उपयोग को यह सही ठहराता है.
अंतिम चरण के रूप में, प्रत्येक वेरिएबल के भार को पाने के लिए ऐजेन्वैल्यू और लोडिंग वैल्यूस का उपयोग किया गया. प्रत्येक वेरिएबल की ऐजेन्वैल्यू को संबंधित घटक पर उस वेरिएबल के पूर्ण लोड से गुणा किया गया. इसके बाद भार हासिल करने के लिए प्रत्येक वेरिएबल के लिए सभी घटकों पर इसे सारांशित किया गया.
गणितीय रूप से, इसे इस प्रकार दिखाया जा सकता है.
wi = |Lij| Eij
जहां
ith वेरिएबल का भार, wi है
jth घटक का ऐजेन्यवैल्यू, Ei है
jth घटक पर ith वेरिएबल की लोडिंग वैल्यू, Lij है
i = 1, 2, 3…n वेरिएबल्स, j = 1,2,3…k घटक है.
इस सूत्र का उपयोग करते हुए, प्रत्येक वेरिएबल के लिए भार नीचे की सूची में दर्शाए गए हैं.
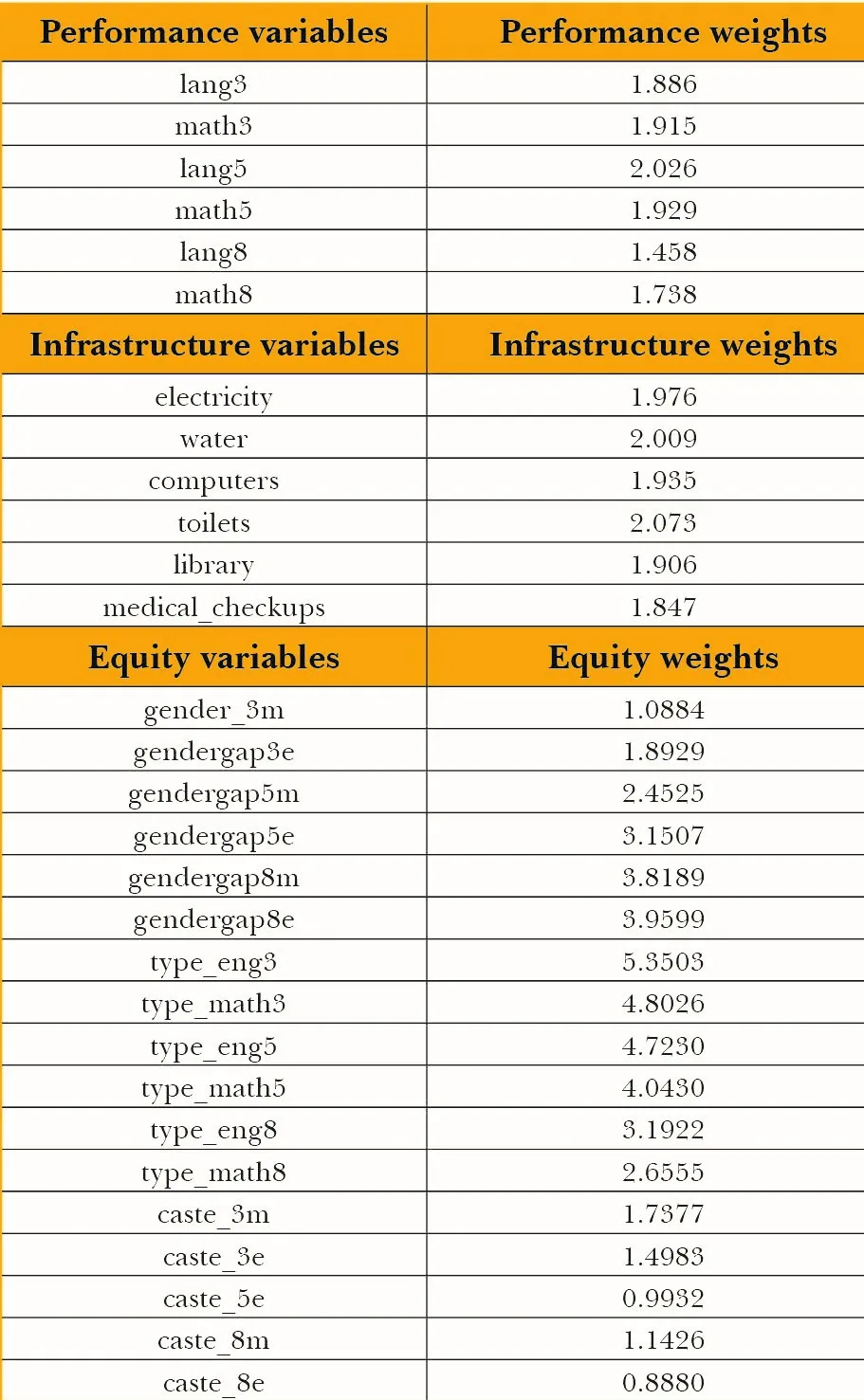
स्त्रोत : स्वयं लेखकों का.
[i] Joshua Angrist and Alan Krueger, “Does Compulsory School Attendance Affect Schooling and Earnings?” The Quarterly Journal of Economics 106, no. 4 (1991): 979–1014.
[ii] Eric Hanushek and Ludger Woessmann, “Do better schools lead to more growth? Cognitive skills, economic outcomes, and causation.” Journal of economic growth 17, no. 4 (2012): 267-321.
[iii] Adriana Lleras-Muney, “The relationship between education and adult mortality in the United States.” The Review of Economic Studies 72, no. 1 (2005): 189-221.
[iv] Lance Lochner and Enrico Moretti, “The effect of education on crime: Evidence from prison inmates, arrests, and self-reports.” American economic review 94, no. 1 (2004): 155-189.
[v] Karthik Muralidharan and Michael Kremer, “Public and private schools in rural India.” Harvard University, Department of Economics, Cambridge, MA 9 (2006): 10-11.
[vi] “Flash Statistics on School Education – U-DISE+” (National Institute of Educational Planning and Administration, 2021).
[vii] “Annual Status of Education Report (Rural) 2019” (ASER Center, 2020).
[viii] Khalid Malik, “Human development report 2013. The rise of the South: Human progress in a diverse world.” UNDP-HDRO Human Development Reports (2013).
[ix] “The Education for All Development Index,” Global Education Monitoring Report (UNESCO, 2015).
[x] Antonio Villar, “The Educational Development Index: A Multidimensional Approach to Educational Achievements through PISA.” (2013).
[xi] “School Education Quality Index,” NITI Aayog, National Institution for Transforming India, Government of India, 2019.
[xii] Anjali Meena and Anima Vaish, “Inter-state Appraisal of School Education Development in India.” Journal of Xi’an University of Architecture Technology, 12 (3), 171-185 (2020).
[xiii] “National Achievement Survey Class III, V & VIII – NCERT” (National Council of Education Research and Training, 2021).
[xiv] “Flash Statistics on School Education – U-DISE+” (National Institute of Educational Planning and Administration, 2021).
[xv] Using t-test, significant at less than 5% (P-Value: 0.038)
[xvi] Using t-test, significant at less than 1% (P-Value: 0.000)
[xvii] “Impact of National Education Policy 2020 and Opportunities for Stakeholders” (KPMG, 2020).
[xviii] Glen Stephanie, “Kaiser-Meyer-Olkin (KMO) Test for Sampling Adequacy,” Statistics How To, 2021.
The views expressed above belong to the author(s). ORF research and analyses now available on Telegram! Click here to access our curated content — blogs, longforms and interviews.

Vanshika Surana is an Applied Mathematics graduate from FLAME University Pune.
Read More +




