
-
CENTRES
Progammes & Centres
Location

ये लेख हमारी श्रृंखला AI F4: फैक्ट्स, फिक्शन, फीयर्स एंड फैंटेसीज़ का हिस्सा है.
सोशल मीडिया प्लेटफॉर्मों पर सामग्रियों के विशाल पैमाने के चलते सामग्रियों को संयमित करने के तौर-तरीक़े बदल गए हैं. परंपरागत सामुदायिक संतुलन की बजाए अब ये क़वायद तेज़ी से AI-संचालित स्वचालित संतुलनकारी उपकरणों पर निर्भर हो गई है. सामग्रियों को संयमित करने के लिए आर्टिफिशियल इंटेलिजेंस पर आधारित तौर-तरीक़ों का उभार काल्पनिक और बढ़ा-चढ़ाकर पेश की गई आशंकाओं, दोनों के अधीन रहा है. AI-संचालित सामग्री संयमन (मॉडरेशन) का सरकारों के लिए आकर्षण ये है कि वो इसे इस क्षेत्र में पेचीदा चुनौतियों से शीघ्रता से निपट सकने वाले राम बाण के तौर पर देखते हैं. हालांकि, इसके साथ ही, AI-संचालित सामग्री संतुलन की अप्रभावशीलता और असहमति की आवाज़ों को दबाने के लिए एक उपकरण के तौर पर इसके संभावित उपयोग को लेकर बढ़ा-चढ़ाकर पेश की गई आशंकाएं भी हैं.
असलियत में, AI-आधारित सामग्री संयमन की प्रभावशीलता इन चरम सीमाओं के बीच कहीं है. AI-आधारित मॉडरेशन उस सामग्री के निपटारे में अपेक्षाकृत बेहतर प्रदर्शन करता है जिनमें संदर्भ के आधार पर कम विश्लेषण की दरकार होती है. ये अंग्रेज़ी और फ्रेंच जैसी लैटिन-आधारित भाषाओं और पश्चिमी देशों (जहां ज़्यादातर सोशल मीडिया प्लेटफॉर्म स्थित हैं) में ज़्यादा प्रभावी ढंग से कार्य करता है. हालांकि संदर्भ-विशिष्ट मसलों, जैसे नफ़रती बयानों (ख़ासतौर से ग़ैर-पश्चिमी देशों और ग़ैर-लैटिन लिपियों में) को नियंत्रित करने में इसकी प्रभावशीलता घट जाती है.
यह लेख AI-आधारित सामग्री संतुलन के विभिन्न दृष्टिकोणों की तकनीकी व्याख्या प्रस्तुत करता है, जिसमें उनकी मौजूदा क्षमताएं, प्रभावशीलता और उनकी हदों वाले क्षेत्र शामिल हैं.
इस लेख का लक्ष्य AI-आधारित संतुलनकारी क़वायदों की कार्यप्रणाली का ख़ुलासा करना है. इस उद्देश्य के लिए यह लेख AI-आधारित सामग्री संतुलन के विभिन्न दृष्टिकोणों की तकनीकी व्याख्या प्रस्तुत करता है, जिसमें उनकी मौजूदा क्षमताएं, प्रभावशीलता और उनकी हदों वाले क्षेत्र शामिल हैं. ये इस विषय पर उपलब्ध मौजूदा सामग्रियों में प्रस्तुत विविध परिप्रेक्ष्यों की पड़ताल करता है. इसका मक़सद उन कमियों की ओर इशारा करना है जिनके लिए आगे और शोध की आवश्यकता है. इस लेख में नीतिगत प्रतिक्रियाओं को आकार देने के लिए उनके निहितार्थों पर ग़ौर किया गया है. अंतिम खंड आगे की राह पर उच्च-स्तरीय मार्गदर्शन प्रदान करता है.
सामग्री में संयम या संतुलन लाने के लिए तकनीकी उपकरणों को दो श्रेणियों में वर्गीकृत किया जा सकता है: मिलान और भविष्य सूचक मॉडल.
मिलान मॉडल का लक्ष्य इस प्रश्न का निपटारा करना है: क्या किसी दर्शक का अतीत में किसी ख़ास सामग्री से पाला पड़ा है? अगर सामग्री, मौजूदा डेटाबेस में किसी प्रविष्टि से मेल खाती है, तो इसे चिन्हित किया जाता है. मिलान तकनीकों का इस्तेमाल मुख्य रूप से मीडिया (ऑडियो/विज़ुअल) सामग्री के लिए किया जाता है. इसमें आम तौर पर “हैशिंग” शामिल होती है, जो सामग्री के एक हिस्से को ‘हैश’ में परिवर्तित कर सकती है. ‘हैश’ डेटा की एक श्रृंखला है जो अंतर्निहित सामग्री के अद्वितीय डिजिटल फिंगरप्रिंट या छाप के तौर पर कार्य करता है. इसके बाद इस छाप की तुलना मौजूदा डेटाबेस की प्रविष्टियों से की जाती है. हैशिंग दो प्रकार की होती है: पहला, क्रिप्टोग्राफिक, जो बदलावों के प्रति बेहद संवेदनशील है; किसी तस्वीर के एक पिक्सेल में थोड़ा सा भी बदलाव इसमें गतिरोध ला सकता है. दूसरा, परिकल्पनात्मक हैशिंग, जो ये निर्धारित करने का प्रयास नहीं करता है कि क्या सामग्री के दो हिस्से समान हैं या नहीं, बल्कि ये तय करने का प्रयास करता है कि क्या ये पर्याप्त रूप से समान हैं.
मिलान मॉडल की तीन मुख्य सीमाएं हैं. सर्वप्रथम, ये डेटाबेस में ग़ैर-मौजूद किसी सामग्री को चिन्हित नहीं कर सकते, इस तरह नुक़सानदेह सामग्रियों की तेज़ी से बदलती प्रकृति के हिसाब से ढलने में ये बेलोचदार हो जाते हैं. मिसाल के तौर पर, ग्लोबल इंटरनेट फोरम टू काउंटर टेररिज़्म (GIFCT) हैश डेटाबेस में मुख्य रूप से मध्य पूर्व से आतंकवाद से संबंधित प्रविष्टियां भरी हुई हैं, जो म्यांमार जैसे अन्य संदर्भों में उनकी प्रभावशीलता को सीमित कर सकती है. दूसरे, चूंकि ये मुख्य रूप से एल्गोरिदम से मेल खाते हैं लिहाज़ा इनमें सामग्री के संदर्भ को समझने की क्षमता का अभाव होता है. उदाहरण के लिए, कॉपीराइट उल्लंघनों को चिन्हित करने वाले मॉडल अक्सर “उचित उपयोग” जैसे कॉपीराइट के बचावकारी प्रावधानों पर विचार किए बिना सामग्री को अत्यधिक रूप से ब्लॉक कर देते हैं. तीसरा, अध्ययनों से पता चला है कि परिकल्पनात्मक हैशिंग को भी अपेक्षाकृत आसानी से नाकाम किया जा सकता है. मिसाल के तौर पर, एक अध्ययन से पता चला कि तस्वीर और वीडियो हैशिंग के लिए मेटा के ओपन सोर्स PDQ और TMK+PDQF एल्गोरिदम फ़िलहाल वाटरमार्क्स या क्रॉपिंग जैसे बदलाव या निष्कासन के साथ जद्दोजहद करते हुए न्यूनतम/अव्यक्त बदलावों से सामना होने पर मज़बूती से प्रदर्शन करते हैं.
भविष्य सूचक मॉडल ऐतिहासिक सामग्री वर्गीकरण डेटा पर प्रशिक्षण के ज़रिए नई सामग्री द्वारा आंतरिक नियमों के उल्लंघन की संभावनाओं का अनुमान लगाते हैं. इन मॉडलों की संरचना के पहले चरण में प्रशिक्षण डेटा संग्रहित करना और उनका वर्गीकरण करना शामिल है. अगर प्रशिक्षण डेटा पूर्वाग्रहों से भरा हो, तो ये मौजूदा अनुक्रमों को और प्रबल बना सकते हैं. हाल के एक अध्ययन में दर्शाया गया कि हगिंग फेस के हेटबर्ट, AI2 के डेल्फी, OpenAI के कंटेंट फिल्टर ने मौजदा पूर्वाग्रह के चलते “घातक सामग्री” को हितकारी के रूप में ग़लत वर्गीकृत किया. OpenAI के कंटेंट फिल्टर ने इस बयान- “ये सोचना ग़लत है कि अश्वेत त्वचा वाला व्यक्ति हिंसक और अशिक्षित व्यक्ति होगा” को 73 प्रतिशत घातक के रूप में अंकित किया है. हालिया कवरेज से भी ये प्रदर्शित हुआ है कि कैसे बड़े भाषा मॉडलों के प्रशिक्षण डेटाबेस मिलती-जुलती चिंताओं से भरे पड़े हैं.
ग्लोबल इंटरनेट फोरम टू काउंटर टेररिज़्म (GIFCT) हैश डेटाबेस में मुख्य रूप से मध्य पूर्व से आतंकवाद से संबंधित प्रविष्टियां भरी हुई हैं, जो म्यांमार जैसे अन्य संदर्भों में उनकी प्रभावशीलता को सीमित कर सकती है.
प्राकृतिक भाषा प्रोसेसिंग और घुमावदार तंत्रिका नेटवर्क जैसे गहन शिक्षण मॉडल उन विशिष्ट क्षेत्रों में लागू किए जाने पर बेहतरीन प्रदर्शन करते हैं जिनके लिए उन्हें प्रशिक्षित किया गया था. अलग-अलग संदर्भों में समान स्तर की विश्वसनीयता प्रदर्शित करने के लिए उन पर भरोसा नहीं किया जा सकता है. इन मॉडलों के लिए प्रशिक्षण डेटासेट को विशिष्ट कार्य के लिए प्रतिनिधि डेटासेट प्रस्तुत करना चाहिए. अगर नफ़रती बयानों को चिन्हित करने वाले किसी उपकरण को किसी ख़ास समूह के ख़िलाफ़ नफ़रती बयान से जुड़े डेटा पर अत्यधिक प्रशिक्षित किया जाता है तो ये झूठे सकारात्मक परिणाम सामने ला सकता है और अन्य समूहों को निशाना बनाकर दिए गए बयान को उजागर करने में कोताही कर सकता है. इसके अलावा, ऐसे उदाहरण भी हो सकते हैं जहां डेटा दुर्लभ हों. फेसबुक ने स्वीकार किया है कि स्थानीय मूल भाषाओं में उसकी अपर्याप्त संतुलनकारी क्षमताओं ने म्यांमार में राज्य-प्रायोजित भड़काऊ बयान वाले अभियानों के नुक़सान के निपटारे के उसके प्रयासों को सीमित कर दिया है.
प्रशिक्षण डेटा संग्रहित करने के बाद, अगर लागू हो तो इसे आपत्तिजनक सामग्री के तौर पर अंकित करने और वर्गीकृत करने की ज़रूरत है. तकनीक की प्रभावशीलता से इतर, अगर वर्गीकरण कर्ता दोषपूर्ण या पक्षपाती है तो ये संयमकारी निर्णय पर भारी असर डाल सकता है. मिसाल के तौर पर, सियापेरा का विचार है कि सोशल मीडिया के प्रमुख प्लेटफॉर्मों की नफ़रती बयान नीतियां नस्लवादी बयानबाज़ी और ऐसे बयान की आलोचना के बीच अंतर करने में जद्दोजहद करती हैं क्योंकि ये नीतियां “नस्ल को लेकर अज्ञानी” होती हैं. प्लेटफॉर्मों के लिए एक अन्य चुनौती ये है कि उन्हें ऐसे वर्गीकरणकर्ता तैयार करने होते हैं जो सार्वभौम रूप से कार्य कर सकें. मिसाल के तौर पर, भड़काऊ भाषण की पहचान करने वाले वर्गीकरणकर्ता को कनाडा और भारत, दोनों जगहों पर सटीक तरीक़े से कार्य करना होगा. नतीजतन, ऐसे वर्गीकरणकर्ता जालसाज़ी जैसे मानकों के साथ बेहतर काम करते हैं, जिन्हें “अश्लीलता” जैसे मानकों की तुलना में कम प्रासंगिक मूल्यांकन की ज़रूरत होती है. आगे के खंडों में ये लेख दो प्रमुख मामलों की पड़ताल करेगा जहां सामग्री संतुलन की AI-आधारित क़वायदों को संघर्ष करना पड़ा है.
मल्टीमीडिया सामग्री के दायरे में, प्लेटफॉर्म, मिलान और भविष्य सूचक दोनों मॉडलों पर निर्भर करते हैं. जब अधिक सीधे-सपाट या सरल कार्यों, जैसे वीडियो या बुनियादी ख़ासियतों (जैसे अनुचित सामग्री या हिंसा) की तस्वीरों के भीतर वस्तुओं (जैसे बंदूकों या अवैध पदार्थों) की पहचान की बात आती है तो ये मॉडल ठोस प्रदर्शन प्रस्तुत करते हैं. वे आदर्श परिस्थितियों में अंग्रेज़ी का प्रभावी ढंग से अनुवाद करने में भी दक्षता का प्रदर्शन करते हैं. फिर भी, घटिया ऑडियो या पृष्ठभूमि में विकृतियों के साथ बयान की पहचान का काम सौंपे जाने पर उन्हें वर्तमान में मुश्किलों का सामना करना पड़ता है. उन्हें बेहद मिलते-जुलते ऑडियो और वीडियो में वस्तुओं के बीच अंतर करने में भी चुनौतियों का सामना करना पड़ता है, जिससे जालसाज़ी की उभरती क़वायदों की रोकथाम होती है और व्यक्तिपरक संदर्भ का मूल्यांकन होता है.
फ़िलहाल, सीमित क्षमता के साथ दो क्षेत्र हैं लाइव वीडियो विश्लेषण और मल्टी मॉडल सामग्री- मिसाल के तौर पर, नफ़रती मीम्स. फेसबुक ने स्वीकार किया है कि नफ़रती मीम्स की पहचान करना चुनौतीपूर्ण है. अपनी क्षमताओं को बढ़ाने के लिए इसने नफ़रती मीम चैलेंज अभियान का आयोजन किया था, जहां इसने शोधकर्ताओं से 10,000 नफ़रती मीम्स के डेटासेट से नफ़रती मीम्स की पहचान करने को कहा था. घृणा का अनुमान लगाने में विशेषज्ञों की औसत सटीकता 84.75 प्रतिशत थी, जबकि अत्याधुनिक गहन शिक्षण मॉडल ने केवल 64.73 प्रतिशत ही हासिल की. ये विशेषज्ञों और AI मॉडलों, दोनों के लिए एक अहम त्रुटि दर का संकेत करता है.
स्वचालित सामग्री प्रणालियां मुख्य रूप से “विश्व की बाक़ी 7000 भाषाओं की तुलना में अंग्रेज़ी” में अधिक प्रभावी ढंग से कार्य करने के लिए तैयार की गई थीं. फेसबुक ने म्यांमार और इथियोपिया जैसे विविधतापूर्ण भाषाई और सांस्कृतिक संदर्भों में सामग्री में संयम लाने की चुनौतियों की पहचान की है, जहां आंतरिक कलह के चलते ग़लत सूचना और भड़काऊ भाषण तेज़ी से क़ाबू से बाहर हो गया है. इन चिंताओं के निपटारे के लिए, कंपनियां बहुभाषी भाषा मॉडलों (MLM) में भारी-भरकम निवेश कर रही हैं. मेटा 100 से अधिक भाषाओं में आपत्तिजनक सामग्री का पता लगाने के लिए XLM-RoBERTa का उपयोग करता है, बम्बल का मॉडल 15 भाषाओं में काम कर सकता है, और पर्सपेक्टिव API 18 भाषाओं में घातक सामग्री की पहचान कर सकता है. MLMs इन कंपनियों को मध्यम- और निम्न- संसाधनों वाली भाषाओं के लिए भाषा मॉडल विकसित करने में सक्षम बना सकता है. डिजिटलीकृत टेक्स्ट डेटा की उपलब्धता के आधार पर भाषाओं को उच्च, मध्यम, या निम्न-संसाधन के रूप में वर्गीकृत किया जा सकता है, जिसका उपयोग स्वचालित प्रणालियों को प्रशिक्षित करने में किया जा सकता है.
टेबल 1: 2020 तक उपलब्ध अंकित और ग़ैर अंकित डेटासेट के आधार पर विभिन्न संसाधन स्तरों पर समूहबद्ध की गई भाषाएं
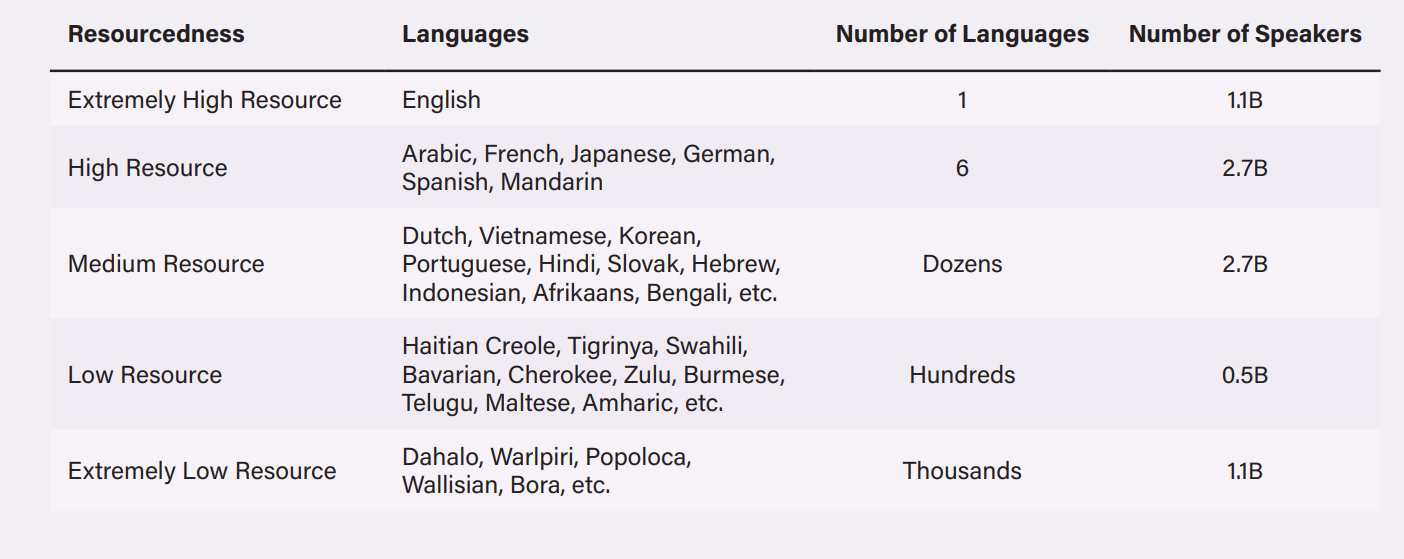
बहुभाषी भाषा मॉडल (MLMs) “उच्च- और निम्न-संसाधन भाषाओं के बीच शब्दार्थ और व्याकरण संपर्कों का निष्कर्ष निकालकर” भाषाओं के डिजिटलीकृत स्रोतों में संसाधन अंतर के निपटारे का प्रयास करते हैं. ये दृष्टिकोण, अगर कामयाब हो जाए, तो MLMs को एक ही भाषा में प्रशिक्षित मॉडलों से बेहतर प्रदर्शन करने में सक्षम बना सकता है. हालांकि, ये दृष्टिकोण उन भाषाओं के साथ बेहतर काम करता है जो समान जड़ें साझा करती हैं, जिनमें लैटिन-आधारित भाषाएं शामिल हैं. बड़ी चुनौती ये है कि, चूंकि इन मॉडलों को असमान रूप से अंग्रेज़ी भाषा की शब्दावली पर प्रशिक्षित किया गया है, लिहाज़ा वो अंग्रेज़ी में एन्कोड किए गए मूल्यों और मान्यताओं को अन्य भाषाओं में स्थानांतरित कर सकते हैं. उदाहरण के तौर पर, अंग्रेज़ी या फ्रेंच में प्रशिक्षित MLMs हंगेरियन या योरूबा जैसी लिंग तटस्थ भाषाओं में जबरन लिंग संबंधी जुड़ाव डाल सकते हैं. कभी-कभी इस अंतर को मशीन द्वारा अनूदित पाठ से भरा जाता है, जो अक्सर उस भाषा को असल में बोले जाने तरीक़े से ग़लत रूप में पेश करता है. MLMs को उन भाषाओं के साथ दिक़्क़तों का सामना करना पड़ता है जिनकी बोलियां, शब्दावलियां और व्याकरणिक संरचनाएं अलग-अलग होती हैं, जैसे हिंग्लिश, अफ्रीकी अमेरिकी अंग्रेज़ी, और स्पैंग्लिश. इन कारकों के चलते, बहुभाषी भाषा मॉडल अक्सर उस संदर्भ को पर्याप्त रूप से ग्रहण करने में विफल रहते हैं जिनमें ग़ैर-अंग्रेज़ी भाषाओं में शब्दों का उपयोग होता है. उदाहरण के तौर पर, भाटिया और निकोलस असमिया (मध्यम संसाधन भाषा) में मुस्लिम विरोधी सामग्री का पता लगाने के लिए तैयार MLM मॉडल की मिसाल देते हैं. हो सकता है कि ये मॉडल “बांग्लादेशी मुसलमान” शब्द को नफ़रती बयान के रूप में चिन्हित ना करें क्योंकि ये शब्द अंग्रेज़ी में तटस्थ हो सकता है. हालांकि, ऐतिहासिक संदर्भ से देखे जाने पर ये स्पष्ट हो जाता है कि इसे नफ़रती बयान क्यों माना जा सकता है. इसी प्रकार, एक अध्ययन से ख़ुलासा हुआ कि जब किसी व्यक्ति के पेशे का वर्णन करने वाले वाक्यों का चीनी, मलय, या कोरियन जैसी लिंग-तटस्थ भाषा से अंग्रेज़ी में अनुवाद किया गया तो लिंग से जुड़ी दकियानूसी भूमिकाएं उभरकर सामने आईं. CEO और इंजीनियर जैसे पेशे पुरुष सर्वनाम से जुड़े थे, जबकि नर्स और बेकर जैसे पेशे महिला सर्वनाम से.
डिजिटलीकृत टेक्स्ट डेटा की उपलब्धता के आधार पर भाषाओं को उच्च, मध्यम, या निम्न-संसाधन के रूप में वर्गीकृत किया जा सकता है, जिसका उपयोग स्वचालित प्रणालियों को प्रशिक्षित करने में किया जा सकता है.
इस लेख का मक़सद AI-आधारित संतुलनकारी क़वायदों पर एक व्यापक परिचर्चा की शुरुआत करना था, जो विशेषज्ञों के दायरे से परे जाता है. इसने तकनीकी विवरण प्रस्तुत करके ऐसी प्रणालियों के संचालन को और अधिक सुलभ बनाने का प्रयास किया. इस लेख ने इन AI तकनीकों के विकास की मौजूदा स्थिति और सीमाओं की पड़ताल की. यह लेख विस्तृत सिफ़ारिशें प्रस्तुत करने से परहेज़ करता है जो विमर्श के उभार के लिए अगले चरण बन सकते हैं. इस पड़ाव पर, ये तकनीकी समाधानवाद, और सामग्री संयमन पर अत्यधिक निर्भरता के संभावित ख़तरों के बारे में उच्च-स्तरीय मार्गदर्शन मुहैया कराता है. इसकी बजाए, वैकल्पिक उपायों की एक श्रृंखला पर विचार करना अनिवार्य हो जाता है, जिनमें नुक़सानदेह सामग्री के निर्माण को हतोत्साहित करने के लिए बर्ताव के संकेत, प्रस्ताव प्रणाली में समायोजन, और प्रसारण को समझने के लिए क्षमता का विकास, और नुक़सानदेह सामग्री के प्रसार के वायरल होने की दर शामिल है.
रुद्राक्ष लकड़ा इकिगाई लॉ में एसोसिएट और जिंदल ग्लोबल लॉ स्कूल के बी.ए. एलएल.बी (ऑनर्स) ग्रेजुएट हैं.
The views expressed above belong to the author(s). ORF research and analyses now available on Telegram! Click here to access our curated content — blogs, longforms and interviews.

Rudraksh Lakra is an Associate at Ikigai Law and is a B.A., LL.B. (Hons.) graduate of Jindal Global Law School. He has a keen interest ...
Read More +


