
This paper examines how high-value users (HVUs), who are often the first to test out new content, such as a new video, on a recommender system platform provide valuable data for these algorithms and ensure that all subsequent users have a great experience. The paper also explores how the current legal setup, including “terms and conditions” (T&Cs) of major players, fail to give due recognition to the contribution of HVUs.
Introduction
It is now well known that algorithms can lead to unintended consequences (for instance, in the case of big-data mining).
<1> This piece attempts to focus on emerging legal issues in the use of Collaborative Filter Algorithms (CFAs) to generate recommender systems that have now become the tech industry’s staple diet.
<2> Most of these issues, as this paper argues, come from not taking into account a fundamental truth about online services today, which is that they tend to interact differently with different users (which again, is a necessary consequence of “personalised feeds” like the ones used by Facebook, Google or even websites such as Netflix and Amazon). The failure to recognise this phenomenon means that the extant laws, policies or even conversations surrounding the relationship between online service providers and users tend to paint all consumers with a generic brush, not realising that “users” constitute many dynamic and stratified classes who may each have different claims to make from these service providers and different levels of bargaining strength with which to enforce their rights.
What is Collaborative Filtering?
Collaborative filtering (CF) is a popular recommendation algorithm that bases its predictions and recommendations on the ratings or behaviour of other users in the system. The fundamental assumption behind this method is that the opinions of other users can be selected and aggregated in such a way as to provide a reasonable prediction of the active user’s preference. Intuitively, they assume that if users agree about the quality or relevance of some items, then they are likely to agree about other items as well. Thus, as Ekstrand, Riedl and Konstan explain, if a group of users likes the same things as Mary, then, among things she has not seen yet, Mary is likely to like the things the group likes.
<3> Therefore, CF is a method of making automatic predictions (filtering) about the interests of a user by collecting preferences or taste information from many users (collaborating).
<4> This creates a “network effect,” which is typical to the software industry. In effect, most such products display and rely on positive network effects, which means that more usage of the product by any user increases the product's value for subsequent users.
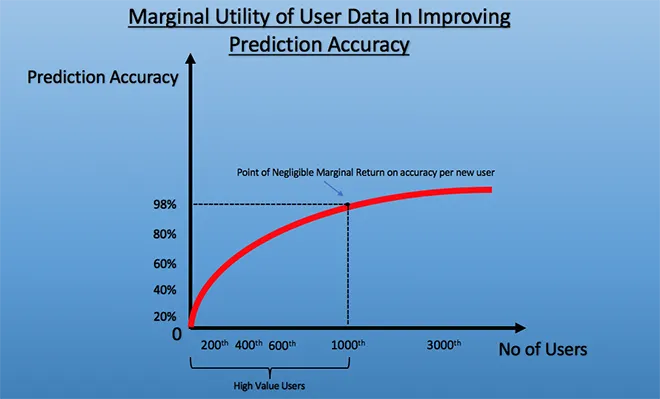
However, this also means that there is a “diminishing marginal utility” with respect to the data that is provided by each new user, i.e., the quantum of change caused in the accuracy of the algorithm diminishes as more and more users have their data added to the set. Thus, the value per user’s data plateaus after a point. As explained in the graph below, there is a rapid rise in accuracy when the first few users’ data (i.e., the data belonging to the HVUs) is assimilated into the system as they provide, hypothetically, around 98 percent of the predictive accuracy of an algorithm. After a point, however, the gains in accuracy by the data provided by each new user becomes negligible.
This is further amplified by the use of the matrix factorisation approach, which is often claimed to be the most accurate approach to reduce the problem from high levels of sparsity in a recommender system’s database.
<5> This technique allows recommender systems to mathematically extrapolate the behaviour of potential users using existing (but sparse) user data.
<6> Simply put, this means that these algorithms need only to rely on a very small set of initial users to achieve accuracy. Consequently, however, it also means that the data belonging to these initial users becomes that much more valuable for the system. Thus, what we effectively have here is a class of “high-value” users who provide the most crucial data for ensuring accuracy, but are on the wrong side of the value chain when it comes to the accuracy of their feed. In other words, every single piece of content that is ever uploaded to any platform using a CFA is pushed purely on an experimental/data-collection objective to a randomly selected group of users, who then generate a solid and accurate feed for everyone else.
Understandably then, those advocating for major corporations using CFAs continue to remain tight-lipped about “testing” content on users while assuring users of the prediction accuracy of their recommender systems.
<7> No one seems to acknowledge that their systems provide varied levels of accuracy depending upon whether the user is one of its most voracious. The one who spends a significant amount of time on the platform in search of new content (e.g., the user who compulsively updates his Facebook news feed) are likely to get the most inaccurate results (which, one might say, is mostly the result of that user’s own actions). However, it is
their reactions that are directly utilised to bring in other users (who, it may stand to reason, are not as voracious as this compulsive user, and could be on the fence about the whole feature/service). This silence is unsurprising, because if it became clear that we, the users, create value for each other at different points of time and for different pieces of content, then those users who inevitably end up being HVUs for a significant amount of content could start expecting to share a slice of the (metaphorical) revenue pie in a manner and quantum separate from other users. Identifying such users will, no doubt, take some data analysis. However, for example, if one were to map just the first 1,000 or so users to whom the most popular/trending video of the day was initially pushed to, it is possible, over a year’s analysis, to be able to isolate a small group of a few hundred users who were the HVUs of multiple trending videos through the year (the “most valuable user class”). If the number is anywhere nearly as significant as suspected, it could lead us to a completely new era with regards to the way people structure contracts with these online service providers using recommender systems.
At the same time, companies often do recognise that there exist such problems with collaborative filtering. The generic solution that they choose to apply is a method called “combined filtering.” This is a form of dual filtering that has aspects from both a collaborative filter and a content-based filter. Using this filtering process, users are divided into various content categories and the relevant content is pushed to the relevant categories. For example, if, from data a user has provided by using the application, it can be ascertained that their main interests lie in the area of sports and music, they will be placed into those categories, along with other users who have similar interests. While this process, to a certain extent, solves the utter arbitrariness of applying only the collaborative filter, it fails to address the central issue, i.e. the HVUs (who are usually also the first users) are still left worse off. This is because, within these content categories, the heavy users still end up being the guinea pigs for the application and the content it chooses to run, and often end up receiving a worse stream of content.
Consider the following example. Assume that there are 200 users within Facebook’s “politics” content category. In this case, the heavy users are likely to get pushed new content first, purely because they access this application and the content far more and are available at more times on the application to have content sent to them. Therefore, the heavy users end up being the first users of the content and are left worse off. This is because as the first users, their content feed is considerably more inaccurate than the user who receives their content last (for the purpose of this example, the 200th user in the category) because their content is far more streamlined. On the other hand, the first user (who is also a heavy user) continues to receive content that they may or may not like. However, Facebook itself benefits more from the first user’s data than the 200th user’s data, and yet, the benefits the users receive do not reflect this gap.
This is potentially problematic as the law, as noted above, is yet to catch up to this reality. A perusal of major laws surrounding the online data space and a look at the current “terms of use” of major recommender systems reveal much, as presented in the next section.
Emerging Legal Issues
That the law continues to treat all users alike leads to a range of concerns. Given that accuracy is built up and improves over time, the factual scenario is such that the HVUs of the service are left at a disadvantage since there is no previous user to help further the algorithm that will then provide recommendations. This means that the HVU, who signed up in the same manner and agreed to the same T&Cs as other users, is left at a disadvantage even though the HVU, being the first user, is a loyalist. In the developing field of technology and privacy, pigeonholing users as one homogenous group, without understanding the need for stratification, has led to a legal scenario where the needs of the different classes of users are not catered to.
The outcome of this lacuna can be cured if users are made aware that they are not always getting the accurate recommendations that the service promises them. Having such disclosure norms in place could lead to multiple outcomes. Heavy users of such services, e.g. Facebook or BookMyShow, could demand that they be informed when their data becomes a part of the “most valuable users class” for generating ratings over particular content pieces over a period of time, such as movies or news items over a six-month or a one-year period. They may additionally demand that they be suitably compensated from the proceeds, if any, earned by the service provider from the relevant content piece/s. For example, if a video titled “Gangnam Style” was to become YouTube’s most popular video on a particular day, the first few thousand users (as opposed to the millions after) may have a legitimate claim that YouTube identify them (using their accounts) and push an appropriate share of revenue earned from ads on the video for that day to that class of users, especially if it turns out that, over a 365-day period, these users were also the HVUs for, say, 50 or 100 of those videos (the exact thresholds are not the central focus in this paper).
However, this gap in the law is not surprising. From the very conception of “Privacy Law” by Warren and Brandeis in the Harvard Law Review, the US system for protecting privacy in the commercial realm has focused on addressing technological innovation. They note: “Recent inventions and business methods call attention to the next step which must be taken for the protection of the person, and for securing to the individual <…> the right “to be let alone’.”
<8> Despite this, the US, which is arguably the one of the most progressive countries when it comes to data privacy, does not have a law in place that delves into specific aspects of user stratification in cases of Internet Service Providers (ISPs). There is no specific federal law that regulates the use of cookies, web beacons, Flash LSOs and other similar tracking mechanisms. Industry stakeholders have worked with government, academics, and privacy advocates to build several co-regulatory initiatives that adopt domain-specific, robust privacy protections that are enforceable by the FTC under Section 5. This means that companies should implement their own policies concerning their own technology. This approach has had notable success, such as the development of the “About Advertising” icon by the Digital Advertising Alliance and the opt-out for cookies set forth by the Network Advertising Initiative. No law, however, mulls over the classes of users that these ISPs cater to and the disadvantage that some of them face.
Similarly, other countries such as India and the Philippines also have laws that ignore the very possibility of user stratification. India has the Information Technology Act, 2008 and the Philippines relies on its Data Privacy Act, 2012. Both these laws aim to protect the fundamental human right to privacy without deliberating over the extent to which this will be possible if the statutes do not correctly identify issues, such as the first user’s disadvantage, that take shape in this day and age.
Canada, however, appears to be slightly ahead of the curve in this matter, owing to several Reports of Findings that the Office of Privacy Commissioner of Canada (“OPC”) has released, addressing issues such as default privacy settings
<9> and social plug-ins.
<10> In addition, the OPC has also released findings indicating that information stored by temporary and persistent cookies is considered to be personal information and, therefore, subject to the Personal Information Protection and Electronic Documents Act, 2000 (PIPEDA). Although this is more than what other countries have done to further the cause of online consumerism, there is still no regulation that deals with the specific class of people that subscribe to the same terms of service as others but still receive service that is of relatively lower quality.
Finally, no discussion of data privacy regulations can be complete without a mention of the European Union (EU). The EU Data Protection Directive was implemented in 1995 and will be superseded by the General Data Protection Regulation, adopted in April 2016. This Regulation, which will be enforceable starting 25 May 2018, by way of regulation number 32, states, “Consent should be given by a clear affirmative act establishing a freely given, specific, informed and unambiguous indication of the data subject's agreement to the processing of personal data relating to him or her… Silence, pre-ticked boxes or inactivity should not therefore constitute consent.”
<11>
Although this regulation, too, does not specifically talk about the disadvantaged class of users, it does allow for ISPs to have separate dialog boxes, which could inform such users of this drawback, since the truth that the services react differently with different users is one that must be explicitly mentioned and brought to the notice of all its users. Without doubt, the EU and the legislations of other countries still lack in as much as they do not talk about the algorithm. However, the aforementioned interpretation of this regulation may be a good place to begin.
Similar issues pervade through the T&Cs of various recommender systems. These T&Cs become an important source of legal discussion as online services are regulated by contractual obligations owed by parties (the service providers and the user) to each other.
However, as far as the T&Cs of the ISPs are concerned, the picture painted is very different from the picture showcased. In the garb of policies such as “We also use this information to offer
you tailored content – like giving
you more relevant search results,”
<12> it seems there is a case of differential treatment wherein “you” are no longer the central target of a better/more accurate feed. At the very least, this clause ought to be reworded to: “We also use this information to offer
others tailored content, like giving
them more relevant search results just as we use
their information to give
you better results.”
In essence, information taken from a small, but equally significant, class of users is not being used for their benefit at all. Their information is used for the benefit of other users who will view the same content at a much later stage. The aforementioned example is that of Google, which, in its privacy policy, further states, “We use information collected from cookies and other technologies, like pixel tags, to improve
your user experience,”
<13> which is far from truth. The fact that a user’s activities will not, at all times, be used to provide better experience to the same user should be an expressly mentioned term.
Facebook, too, states in its privacy policy, “Facebook may also collect information about you from other sources, such as newspapers, blogs, instant messaging services, and other users of the Facebook service through the operation of the service (e.g., photo tags) in order to provide
you with more useful information and a more personalized experience.”
<14> This statement misleads the user to believe that the fact that their activities are being monitored, whether or not benefiting a third party or not, will definitely be beneficial for the user themselves. This draws a false image in the eyes of the user and dispenses with the requirement of full disclosure.
The lacuna that exists in the legislations, alongside the inaccuracy in the terms of major corporations using recommender systems, is a matter of concern and exemplifies the disturbingly urgent need for the legislature to make laws that fill this vacuum, so that the industry ensures full disclosure to each of its users. This, therefore, is an apt emerging issue of tech law. Further, this also means that there is no clear consent obtained from users about using their data to benefit others. For example, unlike beta testing, where users who download the beta version of an app are fully aware that their reaction are being monitored and will be used to better the recommender system, CFA-based systems work dynamically, which means that a new set of predictive data is generated per new piece of content. Thus, there is no one-time collection of data, and the data about how users are reacting is collected and collated continuously.
Conclusion
Policymakers in the space regulating use and monetisation of user data need to pay attention to the legal issues emerging with respect to CFAs. From lobbying for appropriate changes in the “terms of use” of major organisations, to creating more awareness about stratified value provided by users and identifying those users, there is a lot of work that is pending in this area. This paper has attempted to lend clarity in understanding how these systems work and how users interact with them.
Acknowledgement
My heartfelt thanks to Mr. Manish Singh Bisht (Head of Technology, Inshorts), Ms. Shreya Tewari (4th year student at RGNLU, Patiala) and Mr. Sudarshan Srikanth (2nd year student at Jindal Global Law School, Sonepath) for all their assistance in helping me understand the technology at work and with legal research into the multiple jurisdictions and documents examined in this paper. I am grateful for their help.
Endnotes
<1> Solon Barocas and Andrew D. Selbst, “
Big Data's Disparate Impact,”
California Law Review 104, no. 671 (2016).
<2> See
https://www.xcede.co.uk/blog/data-science/the-rise-of-the-recommender-system.
<3> Michael D. Ekstrand, John T. Riedl and Joseph A. Konstan, “
Collaborative Filtering Recommender Systems,”
Foundations and Trends® in Human–Computer Interaction 4, no. 2 (2011): 81–173.
<4> Ibid.
<5> Dheeraj Kumar Bokde, Sheetal Girase, Debajyoti Mukhopadhyay, “Role of Matrix Factorization Model in Collaborative Filtering Algorithm: A Survey,” International Journal of Advance Foundation and Research in Computer (IJAFRC) 1, no. 6 (May 2014).
<6> Meng Xiaofeng and Ci Xiang, School of Information, Renmin University of China, “Big Data Management: Concepts, Techniques and Challenges,”
Journal of Computer Research and Development 01, 2013.
<7> https://code.facebook.com/posts/861999383875667/recommending-items-to-more-than-a-billion-people/.
<8> Warren and Brandeis, “The Right to Privacy,” HARV. L. REV. 4, no. 193 (1890).
<9> PIPEDA,
Report of Findings, #2012-001.
<10> PIPEDA,
Report of Findings, #2011-006.
<11> Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016, “The Protection of Natural Persons with Regard to The Processing of Personal Data and On the Free Movement of Such Data,” repealing Directive 95/46/EC (General Data Protection Regulation)
Official Journal L. 119, no. 1 (2016).
<12> “
Privacy Policy,” Google Services.
<13> Ibid.
<14> “
Privacy Policy,” Facebook.
The views expressed above belong to the author(s). ORF research and analyses now available on Telegram! Click here to access our curated content — blogs, longforms and interviews.




