
It is widely suspected, both in and outside of China, that the Chinese government has under-reported its cases of coronavirus disease 2019 (Covid-19). As the world’s most populous country and the origin of the pandemic, China is ranked only number 42 for the total infected cases at the time of this writing, according to data compiled by Johns Hopkins University. But how inaccurate is China’s inaccurate number? The opacity of the Chinese system makes answering this question challenging.
The pandemic is also a sobering reminder that we have long passed the phase when China’s lack of transparency had few implications to the rest of the world. As China’s global influence grows and its tensions with other countries intensify, whether policymakers and the public have a good grasp on current events in China is more consequential than ever.
The true scale of Covid-19 in China may remain a mystery but reading the tea leaves in Chinese propaganda — that is, the Chinese government’s own words — can offer surprising insight into the severity of the outbreak. This is a tried and true method dating back to at least World War II, and advances in artificial intelligence (AI) technology in recent years have just made this type of propaganda analysis more effective.
The Policy Change Index for Outbreak
As part of the open-sourced Policy Change Index (PCI) project, the author and their team have developed an AI algorithm, the Policy Change Index for Outbreak (PCI-Outbreak), that measures the severity of Covid-19 in China, not through its official statistics but through the words in its propaganda machinery.
Words can speak louder than numbers. On 23 January, 2020, for example, the Chinese government announced a lockdown of Wuhan, which has a population of 11 million, and discussed its necessity at length in state media. However, up to that day, the authorities had only confirmed fewer than 600 cases across the country. Those words might have been driven by the urgency of the outbreak, the government’s intention to impose more lockdowns, or its desire for residents to follow the order. The seriousness of language gives away information that is not contained in the mere hundreds of cases.
Extending this idea through the duration of Covid-19 in China, the PCI-Outbreak, our word-based severity measure on a scale of 0 to 1, provides an interesting contrast with the official number of cases (see the nearby figure).
Figure: Policy Change Index for Outbreak and official Covid-19 cases in China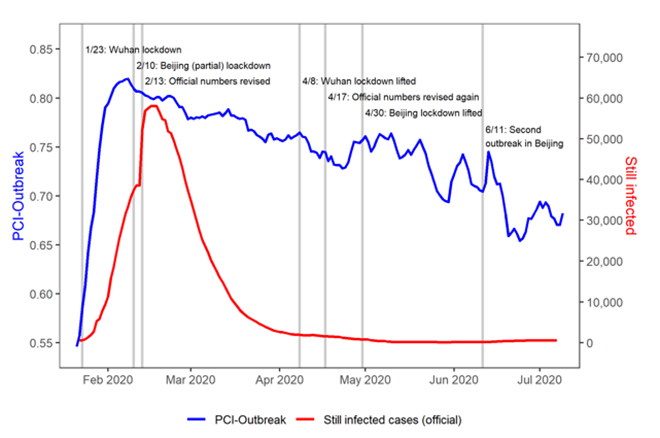
While the PCI-Outbreak and the official number both hit a plateau around the same time in February 2020, the Chinese government’s own words suggest that the pandemic’s severity lessened from March to May at a much slower pace than what the official number was letting on. Moreover, when Beijing had a resurgence of cases in June, the PCI-Outbreak reacted much more sensitively to the new outbreak than the official number, which barely showed any sign of urgency proportional to reality.
The Power of Propaganda Analysis
How is the discrepancy between the Chinese government’s own words and the statistics it released is so pronounced? The answer to this question can be traced back to World War II.
In the fall of 1943, a series of strange German installations on the French coast was discovered by Allied reconnaissance. The Allies watched the construction with much anxiety, as it became apparent that the construction might be some secret weapon sites for attacking London — the world’s most populous city at the time. An opposing view within the Allied forces, however, had it that the installations were a massive hoax by the Nazis with great cunning to divert the Allies’ attention and resources.
Fortunately, the first view prevailed, and the Allies carried out numerous bombardments to destroy what would have otherwise become firing sites for the V-1 flying bomb. According to Dwight Eisenhower, the Allies’ Supreme Commander at the time, had they made the wrong call on these weapon sites, Operation Overload might even have been written off.
Among those who made the correct assessment within the Allied forces were propaganda analysts, whose job was to make inferences about the Nazis drawn solely from reading between the lines of German propaganda. In fact, as documented in the book Propaganda Analysis by political scientist Alexander George, 81 percent of the propaganda inferences about Nazi Germany made by American intelligence analysts during the war proved to be correct—often with amazing accuracy.
Nazi propagandists didn’t mean to reveal their secrets. Yet, their secrets were revealed, because their propaganda content was a product of multiple factors that were of great interest to the Allies: what situation the Nazi regime was in, what actions it intended to take, what goals its propaganda attempted to accomplish, etc. Precisely because these factors determined propaganda content, “reverse-engineering” the content allowed the analysts to draw inferences about those factors.
The same logic applies to pandemic propaganda. Releasing false statistics outright may be trivial, but when a government has to address a severe public health crisis at length in the national media it controls — that’s the case in China — it’s harder to conceal the truth. By “reverse-engineering” how the government talks about the crisis, one could make meaningful inferences about various aspects of the incident that are known to the authorities but not necessarily to the public.
The power of precedents
Directly replicating the Allies’ propaganda analysis method, however, is challenging. The factors mentioned above that determine propaganda content — whether it’s about the progress of weapon deployment or the severity of disease outbreak — are complex and intertwined. Distilling the causal connection between those factors and the (eventual) propaganda content, therefore, is labor- and resource-intensive.
However, if an incident similar to the one at hand had happened before, the precedent would make the propaganda inferences more viable. The causal relationship between the underlying factors and the propaganda content may be peculiar, but when the incident repeats itself, it’s reasonable to assume that a good part of that causal relationship, whatever it might have been, will persist to the issue at hand. Moreover, because propaganda messages (i.e., words) are unstructured data, learning from precedents is made easier by recent breakthroughs in the field of natural language processing that can process and analyze large amounts of text effectively.
The PCI-Outbreak algorithm leverages exactly this convenience of precedents. China went through a similar public health crisis: the 2002-03 severe acute respiratory syndrome (SARS) outbreak. While the scale of this previous episode was much smaller, it nevertheless gives us a rare window to learn the tone and tenor of the Chinese government’s own words as the outbreak waxed and waned in its cycle.
Using SARS as the benchmark, the PCI-Outbreak algorithm “reads” how the Chinese government talks about COVID-19 and locates the time in the SARS epidemic cycle where the SARS-era language then most closely resembles the COVID-era language now. For example, when the propaganda content shows increasing urgency surrounding COVID-19, the algorithm would deem the outbreak on the rise because, when the SARS outbreak was on the rise, the Chinese government’s language was also urgent-sounding. Similarly, when the algorithm sees victory-claiming in the state media, it would naturally make a connection to the waning of SARS outbreak when victory-claiming was also the theme.
This variation of propaganda analysis that relies on the power of precedents is obviously applicable to many other situations. In another study, for example, our research team developed a similar deep learning algorithm, the Policy Change Index for Crackdown (PCI-Crackdown), that predicts whether the 2019-2020 pro-democracy protests in Hong Kong would be faced with a violent military crackdown by learning from the precedent of pro-democracy protests in Tiananmen Square in 1989, when such a crackdown took place and the content of Chinese propaganda evolved leading up to the incident.
The philosopher George Santayana famously said that “those who cannot remember the past are condemned to repeat it.” But the flip side of this resounding wisdom means that, because history does repeat itself, it presents plenty of opportunities for us — or our AI programs — to learn from the past.
The views expressed above belong to the author(s). ORF research and analyses now available on Telegram! Click here to access our curated content — blogs, longforms and interviews.




