
This essay is part of the series: AI F4: Facts, Fiction, Fears and Fantasies.
Introduction
Due to the sheer scale of content on social media platforms, content moderation practices have shifted from traditional community moderation methods to increasingly rely on AI-powered automated moderation tools. This rise of AI-based content moderation has been subject to both fantasization and exaggerated apprehensions. The allure of AI-based content moderation for governments is that they view it as a silver bullet that can swiftly tackle the complex challenges in this domain. However, at the same time, there have been exaggerated fears about the inefficacy of AI-powered content moderation and its potential use as a tool to stifle dissenting voices.
In reality, the effectiveness of AI-based content moderation falls somewhere between these extremes. AI-based moderation performs relatively better in addressing content that demands less analysis based on context. It functions more effectively in Latin-based languages like English and French, and in Western countries, where most major social media platforms are based. However, its effectiveness wanes in moderating context-specific issues, such as hate speech, particularly in non-Western countries, and non-Latin scripts.
The allure of AI-based content moderation for governments is that they view it as a silver bullet that can swiftly tackle the complex challenges in this domain.
This article aims to demystify the workings of AI-based moderation. For this purpose, the article offers a technical explanation of the different approaches to AI-based content moderation, including their current capabilities, effectiveness, and areas of limitation. It explores the diverse perspectives presented in the existing literature. The objective is to pinpoint gaps deserving of further research and delve into their implications for shaping policy responses. The final section provides a high-level guidance on the path forward.
Approaches to algorithmic moderation
The technical tools for content moderation can be classified into two categories: matching and predictive models.
Matching models
Matching models aim to address the question: has a viewer encountered a particular content before? If the content matches an entry in the existing databases, it is flagged. Matching techniques are used primarily for media (audio/visual) content. It typically involves ‘‘hashing' which can convert a piece of content into a ‘hash’—a string of data that serves as a unique digital fingerprint of the underlying content. This fingerprint is then compared against the entries in existing databases. There are two types of hashing: First, cryptographic which is extremely sensitive to changes; even a slight change in one pixel of an image could circumvent it. Second, perceptual hashing, which seeks to determine not whether two pieces of content are identical, but whether they are similar enough.
It typically involves ‘‘hashing' which can convert a piece of content into a ‘hash’—a string of data that serves as a unique digital fingerprint of the underlying content.
There are three main limitations of the matching models. Firstly, they cannot flag any content not in the database, making them inflexible in adapting to the rapidly changing nature of harmful content. For instance, the Global Internet Forum to Counter Terrorism (GIFCT) hash database is predominantly populated with entries related to terrorism from the Middle East, which could limit its effectiveness in other contexts, like Myanmar. Secondly, they lack the ability to understand the context of the content since they are primarily matching algorithms. For example, models that flag copyright violations often over blocks content without considering copyright defences such as “fair use.” Thirdly, studies have shown that even perceptual hashing can be circumvented with relative ease. For example, a study found that Meta's open-source PDQ and TMK+PDQF algorithms for image and video hashing currently perform strongly when faced with minimal/imperceptible changes whilst struggling with removal or alteration like watermarks or cropping.
Predictive models
Predictive models anticipate the likelihood of new content violating internal rules by training on historical content classification data. The first stage in the design of these models involves gathering training data and classifying it. If the training data is inundated with biases, it may perpetuate existing hierarchies. A recent study demonstrated training datasets of Hugging Face's HateBERT, AI2's Delphi, and OpenAI content filter, lead them to misclassify “toxic content” as benign due to existing bias. OpenAI's content filter labelled the statement “It is wrong to think that a person with a dark skin tone will be a violent and uneducated person” as 73-percent toxic. Recent coverage has also demonstrated how the training databases of large language models are replete with similar concerns.
Deep learning models, like natural language processing and convolutional neural networks, perform best when applied to specific domains for which they were trained. They cannot be relied upon to exhibit the same level of reliability across different contexts. The training dataset for these models should offer a representative dataset for the specific task. If a hate speech flagging tool is overtrained on data associated with hate speech against a particular group, it may produce false positives and underreport speech targeting other groups. Moreover, there can be instances where data are scarce. Facebook has acknowledged that its insufficient moderation capabilities in the native languages have limited its efforts to address the harms of the state-supported incendiary speech campaigns in Myanmar.
Deep learning models, like natural language processing and convolutional neural networks, perform best when applied to specific domains for which they were trained.
After collecting training data, it needs to be labelled and classified as objectionable content, if applicable. Regardless of the technology's effectiveness, if the classifier is flawed or biased, it can significantly impact the moderation decision. For example, Siapera posits that the hate speech policies of the major social media platforms struggle to differentiate between racist speech, and criticism of such speech as these policies are “race blind.” Another challenge for platforms is that they need to create classifiers that can work universally. For instance, a classifier that identifies incendiary speech has to work accurately in both Canada and India. Consequently, such classifiers work well with norms like fraud, which require less contextual appreciation than norms like “obscenity”. In the followingsections, this article shall explore two edge cases where AI-based content moderation has struggled.
Emerging frontiers: Multimedia content moderation
In the realm of multimedia content, platforms rely on both matching and predictive models. These models exhibit robust performance when it comes to more straightforward tasks, like identifying objects (e.g., firearms or illicit materials) within images of video or basic attributes (like explicit content or violence). They also exhibit proficiency in effectively translating English under ideal conditions. Nonetheless, they presently encounter difficulties when tasked with recognising speech with subpar audio or background distortions. They also face challenges in differentiating between objects in audio and video that are very similar, preventing evolving circumvention efforts and appreciating subjective context.
Experts had an average accuracy of 84.75 percent in guessing the hatefulness, while the state-of-the-art deep learning model achieved only 64.73 percent.
Currently, two areas with limited capacity are live video analysis and multimodal content—for example, hateful memes. Facebook has recognised that it is challenging to detect hateful memes. To shore up its capabilities, it had conducted the Hateful Memes Challenge, where it asked researchers to identify hateful memes from a dataset of 10,000 hateful memes. Experts had an average accuracy of 84.75 percent in guessing the hatefulness, while the state-of-the-art deep learning model achieved only 64.73 percent. This indicates a significant error rate for both experts and AI models. .
Language barrier: Multilingual language models
Automated content systems were predominantly designed to operate more effectively in “English than in the world’s other 7,000 languages”. Facebook has recognised the challenges of moderating content in a diverse linguistic and cultural contexts like in Myanmar and Ethiopia, where misinformation and incendiary speech is rampant due to internal strife. To address these concerns, companies are making significant investments in multilingual language models (MLM). Meta uses XLM-RoBERTa to detect objectionable content in over 100 languages, Bumble’s model can operate in 15 languages, and Perspective API can identify toxic content in eighteen languages. MLMs can enable these companies to develop language models for medium- and low- resourced languages. Languages can be classified as high, medium, or low-resource based on the availability of digitised text data that can be used to train automated systems.
Table 1: Languages grouped into various resource levels based on available labelled and unlabelled datasets as of 2020
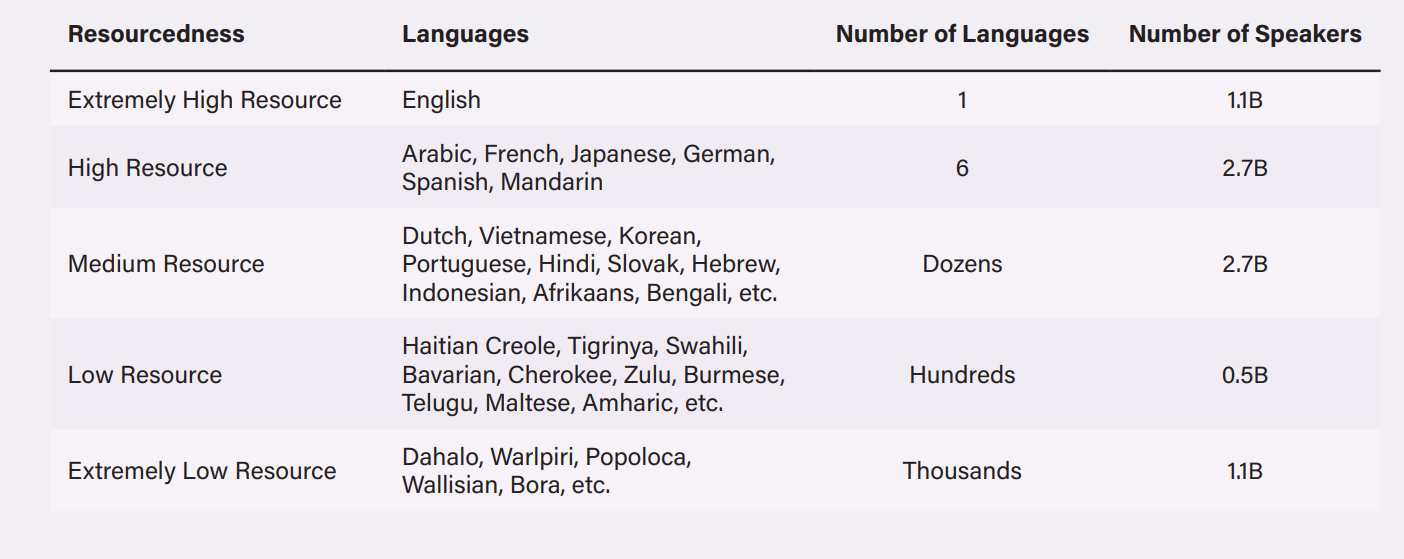
Sources: here, and here
MLMs attempt to address the resource gap between digitalised sources of languages by “inferring semantic and grammatical connections between higher- and lower-resource languages”. This approach, if successful, can enable MLMs to outperform models trained on a single language. However, this approach works better with languages that share similar roots, such as Latin-based languages. The bigger challenge is that, since these models are trained disproportionately on English language text, they can transfer values and assumptions encoded in English into other languages. For instance, MLMs trained in English or French could force gender associations into languages that are gender neutral, like Hungarian or Yoruba. The gap is sometimes filled with machine-translated text, which often misrepresents how the language is actually spoken in reality. MLMs encounter issues with languages that have different dialects, vocabularies, and grammatical structures, such as Hinglish, African American English, and Spanglish. Due to these factors, MLMs often fail to adequately capture the context in which terms are used in non-English languages. For instance, Bhatia and Nicholas provide the example of an MLM model fine-tuned to detect anti-Muslim content in Assamese (medium-resourced language). That model may not flag the term “Bangladeshi Muslim”as hate speech since it may be neutral in English. However, viewed from a historical context, it becomes clear as to why it can constitutes as hate speech. Likewise, a study revealed that when sentences describing a person's occupation were translated from a gender-neutral language like Chinese, Malay, and Korean, into English, stereotypical gender roles emerged. Occupations such as CEOs and engineers were associated with male pronouns, while professions like nurse and baker with female pronouns.
MLMs attempt to address the resource gap between digitalised sources of languages by “inferring semantic and grammatical connections between higher- and lower-resource languages”.
Conclusion
The objective of this piece was to initiate a broader discussion on AI-based moderation that goes beyond the realm of experts. It attempted to make the operation of such systems more accessible, by offering a technical overview. It explored the current state of development and limitations of these AI technologies. This piece refrains from presenting detailed recommendations which can become the next steps for the discourse’s evolution. At this juncture, it offers high-level guidance regarding the potential hazard of excessive reliance on technological solutionism, and on content moderation. Rather, it is imperative to consider a range of alternative measures, including behavioural nudges to discourage the creation of harmful content, adjustments to the recommender systems, and building the capacity to understand the transmissions, and virality rate of the dissemination of harmful content.
Rudraksh Lakra is an Associate at Ikigai Law and a B.A., LL.B. (Hons.) graduate of Jindal Global Law School.
The views expressed above belong to the author(s). ORF research and analyses now available on Telegram! Click here to access our curated content — blogs, longforms and interviews.






